Fellows:林峰生、林廷州、林恆宇、胡馨勻、葉憲周、郭泰竹、郭家諭
Mentor:謝宗震
Project Manager:李苡菲
Project Partner:新北市政府社會局
摘要
新北市高風險中心由100年執行至105年,新北市高風險兒少通報案件累計達66,397案件(平均每年約1萬件),考量此類高風險家庭常面臨多元化之風險,為能協助網絡中的工作人員對於家庭的危機程度有更精確的掌握,可於處理眾多高風險案件時,導入更適宜之資源與服務模式協助,使此類家庭免於再次發生高風險危機或進而演變成更嚴重的兒童虐待案件,如果無法提早找出類似嚴重的家庭,極有可能會發生更嚴重的事件。因此,找出容易重複被通報的「回頭客」以及預測個案是否有機會「進入家暴防治中心」(以下簡稱家防),可望幫助解決以上時間有限但人力不足,並適應多元化風險的問題。
背景說明
新北市為全台灣最大縣市、六都之首,人口數高達400萬人,涵蓋29個行政區,擁有豐富的自然資源及科技進步的城市,但在光鮮亮麗的外表下,社會邊緣的角落正在發生許多鮮為人知的問題,而這些問題可能就發生在你我周遭,關係著社會安全以及未來主人翁的幸福。
新北市高風險家庭服務管理中心(以下簡稱:高風險中心)成立於民國一百年,主要負責進行高風險家庭案件之分級管派與服務狀況追蹤,目的是為了提前預防家庭暴力以及兒童受虐等問題發生,民國101年至105年新北市高風險兒少通報案件累計達66,397件(平均每年約一萬件),等於每一個小時就要處理一件高風險家庭的個案,且是24小時待命、全年無休。
有鑑於此,由D4SG資料英雄計畫組織了一支擁有社工、統計、資工、資料科學以及專案管理背景的團隊,透過高風險中心十萬多筆的資料,經由大數據分析,希望能夠協助高風險中心對於家庭的危機程度有更精確的掌握,可於處理眾多高風險案件時,導入更適宜之資源與服務模式協助,避免再次發生高風險危機或進而演變成更嚴重的兒童虐待案件。
專案目標
新北市是個有著多元文化與族群聚集的城市,約有百分之七十是外移人口,但隨著家庭結構的改變、傳統自掃門前雪觀念的根深柢固。為了要讓兒少能獲得更完善的照護,新北市高風險家庭中心建立一個完善的兒少安全保護網,以普及宣導、預防支持、保護服務三個層級,希望能做出完善預防的工作,避免兒虐事件的發生。
新北市高風險兒少通報案件量平均每年約有10,000件,每人每年約需處理1,666件案件。因此,在如此龐大的案件量中如何更準確的評估每個案件的輕重緩急並且妥善安排人力資源做出最適當的處理著實重要。「預防勝於治療」基於以上種種原因,我們希望可以建立一個良好的預測機制,先找出容易重複進案的「回頭客」以及個案是否有很大風險會「進入家防中心」,再藉由這些因子建立出預測模型,幫助高風險中心人員往後對於這些高風險家庭能進行主動且預先的關懷訪視,對這些家庭的危機程度有更精確的掌握,在處理高風險案件時,導入更適宜之資源與服務模式協助,讓此類家庭免於再度發生高風險危機或進而演變成更嚴重的兒童虐待案件。
資料集介紹
本專案所使用的資料取自於「新北市高風險家庭整合型安全網資訊管理系統」,將資料個案之身分證加密後,整合成單一資料總表,取得近147萬筆原始資料,包含每一個案之重複案件以及個案評估量表、通報表、派案評估表等資訊。重點資訊條列如下:
該案兒少人口變項之資料,包含如:性別、年齡、居住區域、國籍等
每通報案件於通報時經由通報人勾選之風險指標
每通報案件於社工初篩派案時所評估勾選之兒少所遭遇的家庭問題情形 (如經濟問題、就學問題、父母親藥癮問題等)
各網絡局處受理案件後對於案件危機程度的評估資料(以紅黃綠燈進行危機程度區分)
各網絡局處每月對於案件之服務紀錄
資料勾機外部資料情形
「新北市高風險家庭整合型安全網資訊管理系統」橫跨10個局處 (民政、教育、社會、衛生、工務、勞工、警政、消防、原民、資訊中心)與 1,300個窗口。亦勾稽相關外部資料,包含新北市福利補助系統、教育局兒少學籍系統以及兒童虐待保護案件資訊系統,是一個多元整合管理系統。
執行方式
由於工作期程有三個月,因此我們將工作切分成兩段,第一階段包含流程理解、資料盤點、預期成果;第二階段是進行資料清理、資料分析並且撰寫成果報告。
由於在此案之前顧問已有台北市家防專案的經驗,所以對於社工的組織較為了解,也較清楚資料專案的困難之處。最初的一個多月,主要的工作在於理解高風險中心的工作流程,配合資料盤點的結果,利用資料驅動的討論方式收斂到兩個專案目標,首先是避免案件無法結案不斷的重複開案,又或者是個案落入更危險的兒少保護體系 (家暴)。
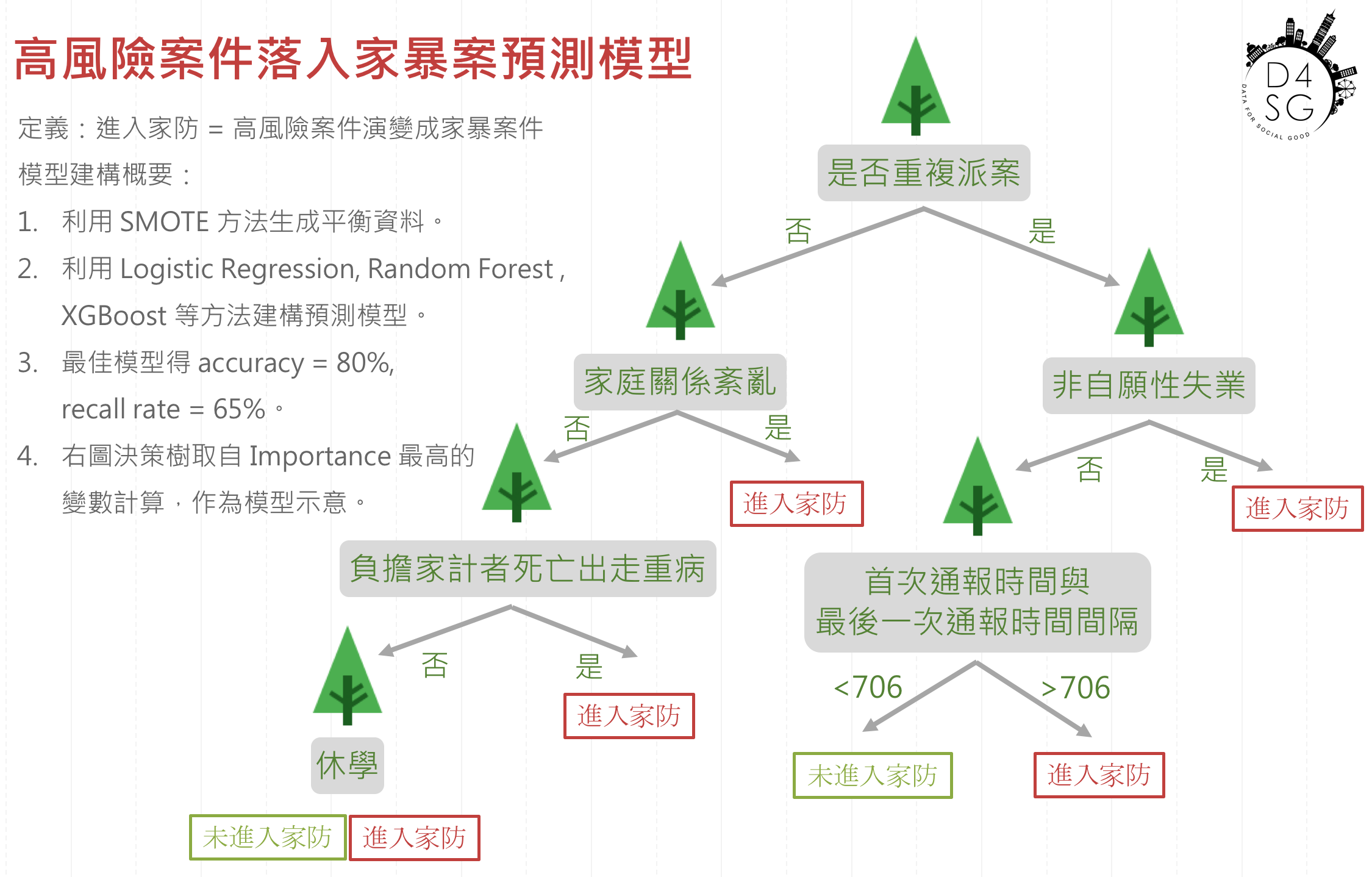
接下來的一個月主要工作是制定資料分析策略,首先進行資料處理,將資訊系統拉出來的資料轉換成可供機器學習模型所使用的資料大表 (data.frame),其中最困難的工作在於如何從凌亂的資料表中,找出高風險中心處理的個案屬於哪個家庭,以及如何做跨表格的合併。接下來是做資料探索,找出與落入家暴問題案件相關的特徵以及派案回頭客的相關特徵。統整這些資料探索結果後本組使用邏輯斯迴歸、支持向量機、隨機森林等演算法針對家暴個案、回頭客個案進行預測,最終選擇準確度高達八成的隨機森林模型作為成果。
資料探索