
兒少保護案件之精準派案
Mentor:謝宗震、楊思
Project Manager:陳映竹
Project Partner:衛生福利部保護服務司
通過文獻梳理,我們發現「風險評估」在兒少保領域的應用在20世紀90年代就已經普及(English & Pecora, 1994),在現如今依然是主要的評估工具。在學術領域,兒少保領域的「風險評估」可被定義為「評估某個既定的(通常是父/母)人在未來可能傷害兒童的一個過程」(Wald & Woolverton, 1990)。據已有研究,通過整理各種主要的風險評估工具,其共同考量的因素不超過三大類別的範圍:兒童特徵或受虐情況,父母特質與家庭環境(尹欣如,2013)。
大數據應用於兒少保領域的風險評估在其他國家早已有所應用,美國聖路易斯華盛頓大學的Jolley(2012)曾用神經網絡模型將風險因素分為靜態因素和動態因素,來預測兒童遭受不良對待的復發。也有學者通過分類和回歸樹分析來對兒童遭受不良對待的復發來進行預測,發現對高風險組有更好的預測力(Sledjeski, Dierker, Brigham & Breslin, 2008)。
一、研究資料與主題

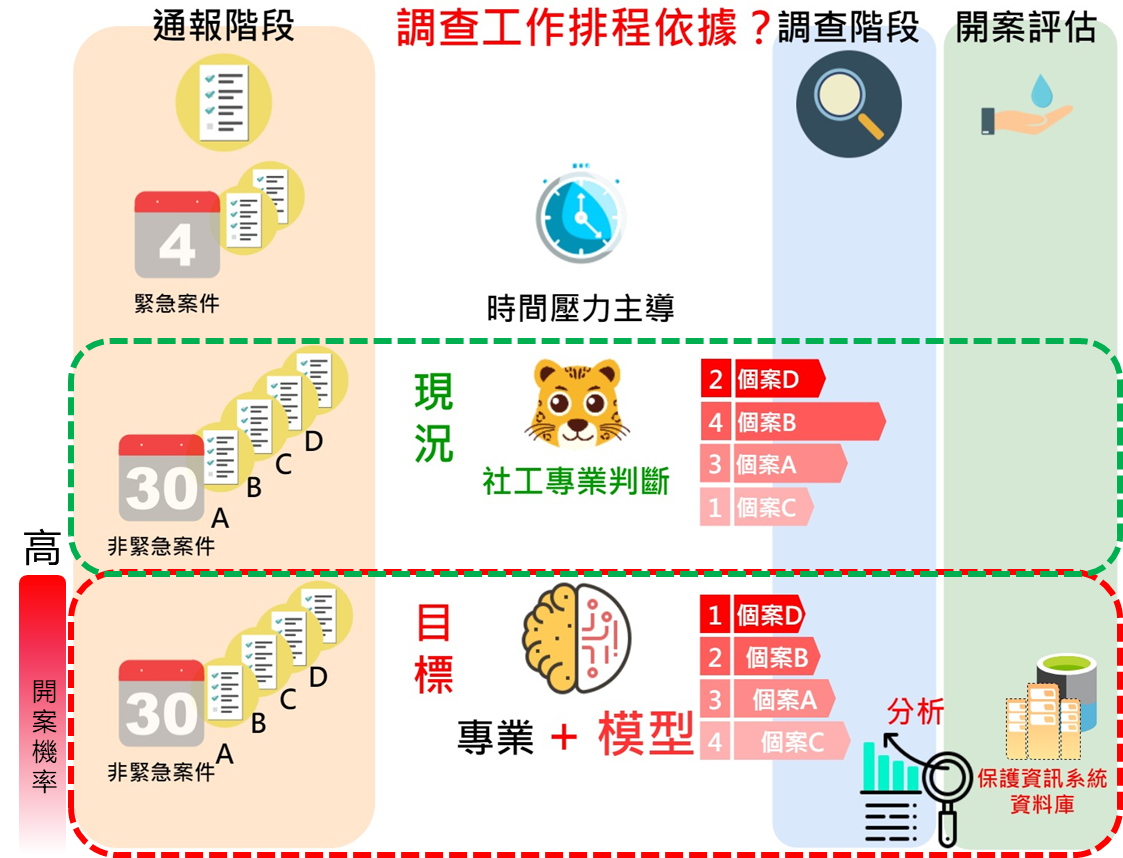
圖 1
主題1:兒少保護通報開案預測
透過通報表資訊預測該案開案與否,提供兒少保社工進入調查階段前案件優先順序參考。分析使用2017年一類案件通報表及關係人基本資料,包含最終開案及未開案案件,共20,165筆。
從通報過渡到調查階段,大量的非緊急案件,現況仰賴社工專業判斷。我們目標是社工不僅是面對當下的通報案件、自身專業判斷,透過分析資料庫中歷史通報案件,建構開案預測模型輔助社工,綜合自身專業與模型結果資訊成為工作排程依據。
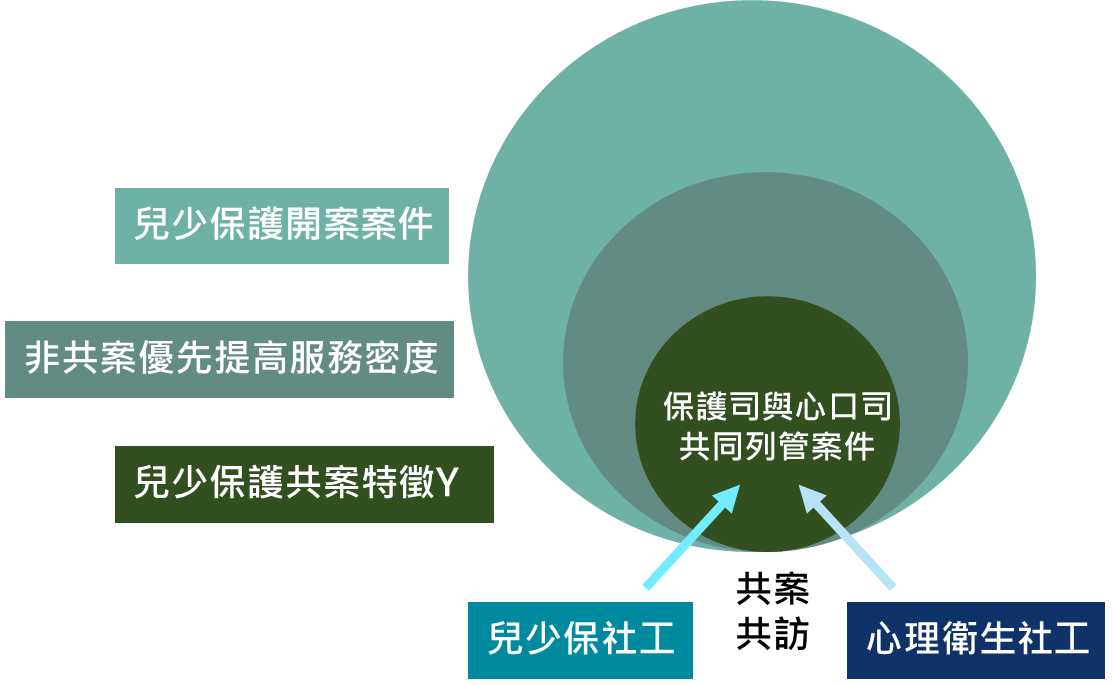
圖 2
主題2:共案特徵預測及訪視優先次序分析
兒少保護開案案件中,透過調查報告找出與「保護司與心口司共同列管案件(共案)」特徵類似,但未有心理衛生社工介入服務(未納入共訪機制)之案件,預先提示兒少保社工提高服務密度及敏感度。分析使用2016和2017年一類案件被害人父母調查報告資料,篩選出最終開案的案件,共13,621筆。
進到服務階段,實務經驗告訴我們保護司、心口司兩個單位共同列管個案,必須有較高服務密度。也已建立保護司兒少保社工、心口司心衛社工的「共案共訪」機制。相對的,非共同列管案件就沒有心衛社工介入服務。即便未納入共訪機制的個案,透過共案特徵預測,預先提示兒少保社工提高服務密度及敏感度,仍可提供綿密的服務。
二、分析手法
主題1:兒少保護通報開案預測模型
使用關聯分析找出通報表填報項目選項中影響開案的重要因素。並透過通報表結構化資料及案情陳述非結構化文字資料,結合自然語言處理(NLP)與Random Forest隨機森林技術建立開案預測模型。
主題2:共案特徵預測及訪視優先次序分析
使用XGboost演算法建立模型。
三、研究發現
主題1:兒少保護通報開案預測
1. 通報表關聯分析
我們希望能夠提供審查通報案的人員哪些因素是會影響到開案與否,如此他們在審閱的過程中能夠更敏銳、更有效率的檢測通報案。我們藉由關聯分析此方法來找出,算是較初步的EDA。
分析的步驟主要有兩項:
(1) 由於通報案的資料缺失嚴重,因此會先用CART決策樹的方法進行遺漏值預測。
(2) 使用apriori演算法跑關連分析。
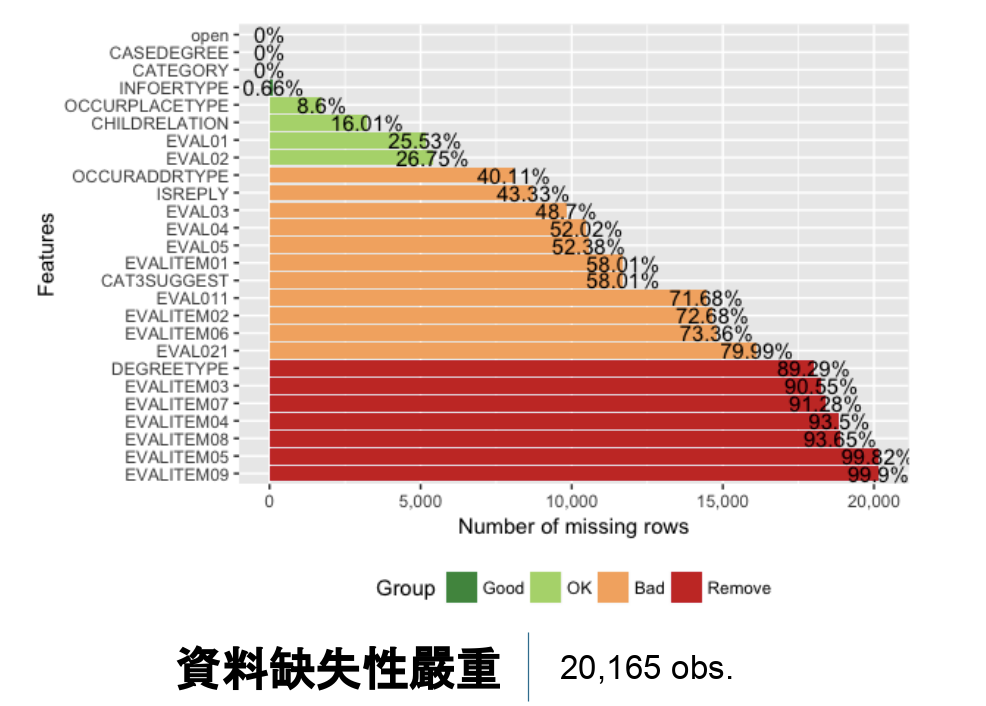 圖 3
圖 3
上圖 3為每顆變數缺失值所佔的比例,可得知滿多資料的缺失性十分嚴重。我們的作法為直接刪除缺失性佔比高於60%的變數,其他便由CART決策樹進行遺漏值預測。
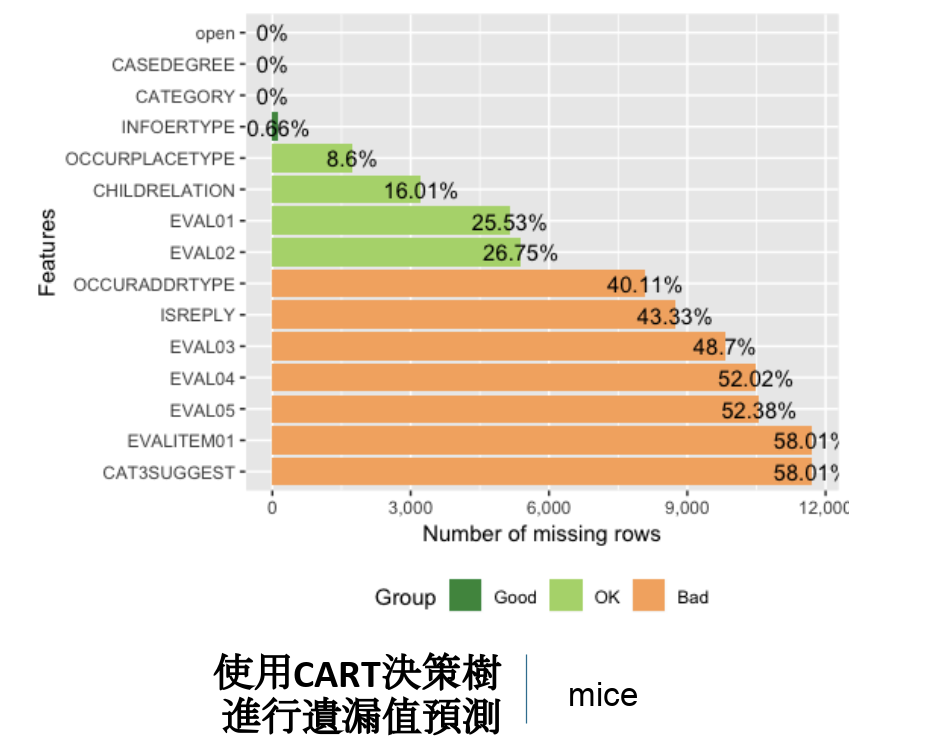
圖 4

圖5
上圖5 的關聯分析是由lift值高到低排序,所選取到與開案與否高度相關的變數有:
- 第三評估指標第一層:身體虐待樣態
- 兒少先前有遭受父母、監護人、實際照顧之人或者其他家庭成員虐待、不當對待或疏忽的紀錄
- 通報日期不是在週末
- 受理日期不是落在週末結束後一天
- 母親有家暴受虐者紀錄
- 先前沒有身體虐待的紀錄、或沒有正處於家暴事件當中、或照顧者沒有精神疾病、或是濫用藥物的問題、或兒童不是處於恐懼或無助狀態中
- 兒童沒有表現出需要立即進行心理健康評估的行為
其中1、2、5是比較直觀能理解的變數,兒童有被虐待的徵兆,或是母親有遭受到家暴,這些都會造成開案率比較高。而6就滿值得後續深入探討的,我們猜想它所代表的是「初犯」,之前沒有任何不良紀錄的兒少案件會造成開案率較高。7目前尚未確定他背後所代表的意義,為什麼兒童沒有表現出需要立即進行心理健康評估的行為反而開案率較高。
希望此關聯分析能夠協助社工人員在審閱開案案件時,能夠利用這些挑出來的變數,更快速,更精確的分析案件。
2. 通報表開案預測模型
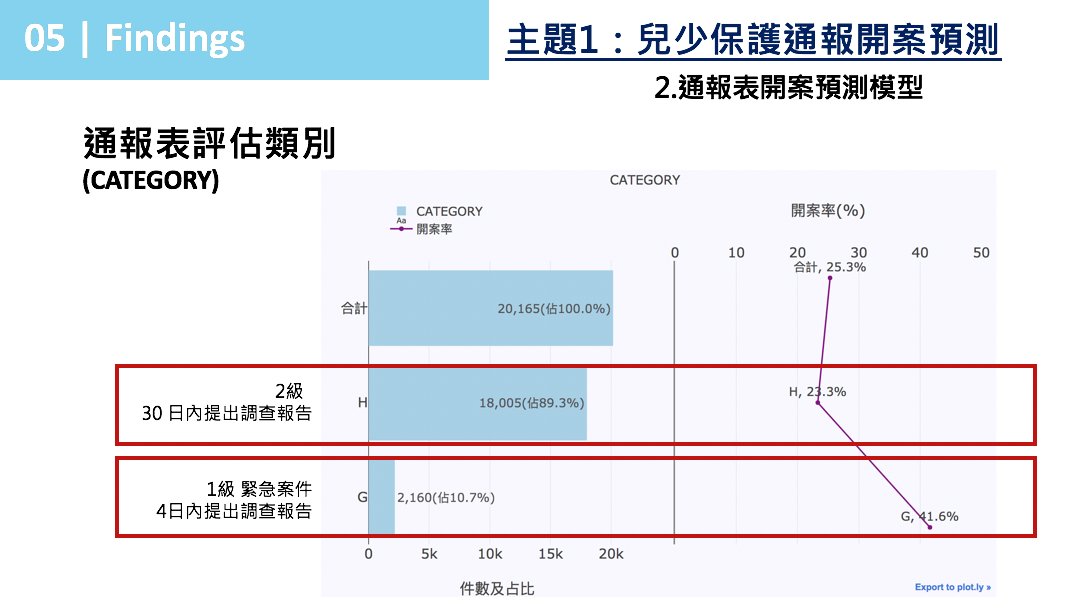 圖 6
圖 6
當兒少保護通報表通報時流程上會針對通報案件進行分級,分級1級之通報案件須在4日內提出調查報告,2級案件須在30日內提出調查報告。圖 6以這次2017年的通報表1級案件約佔10.7%(開案率41.6%),2級案件約佔89.3%(開案率23.3%)。考量到實際通報流程,將此次樣本資料區分1級&2級案件個別建模。
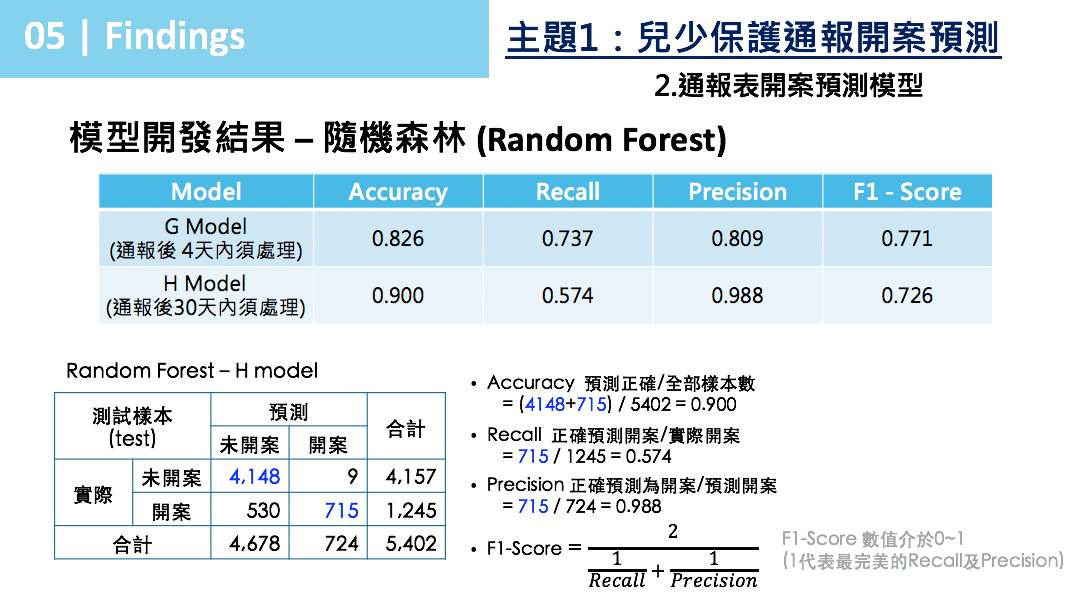 圖 7
圖 7
經由通報表資料預處理、新增變數(如發生時間與通報時間日數、通報時間是否發生在寒暑假等)等,以隨機森林(Random Forest)進行兩個子模型開發(見圖 7):
- G Model – 1級案件(通報後4日內須提出調查報告):
模型預測正確率82.6%,Recall(即測試樣本中實際開案案件,被模型預測正確有開案比率)73.7%,Precision(即測試樣本中模型預測開案案件中,正確預測有開案比率)80.9%。
- H Model – 2級案件(通報後30日內須提出調查報告):
模型預測正確率90.0%,Recall(即測試樣本中實際開案案件,被模型預測正確有開案比率)57.4%,Precision(即測試樣本中模型預測開案案件中,正確預測有開案比率)98.8%。
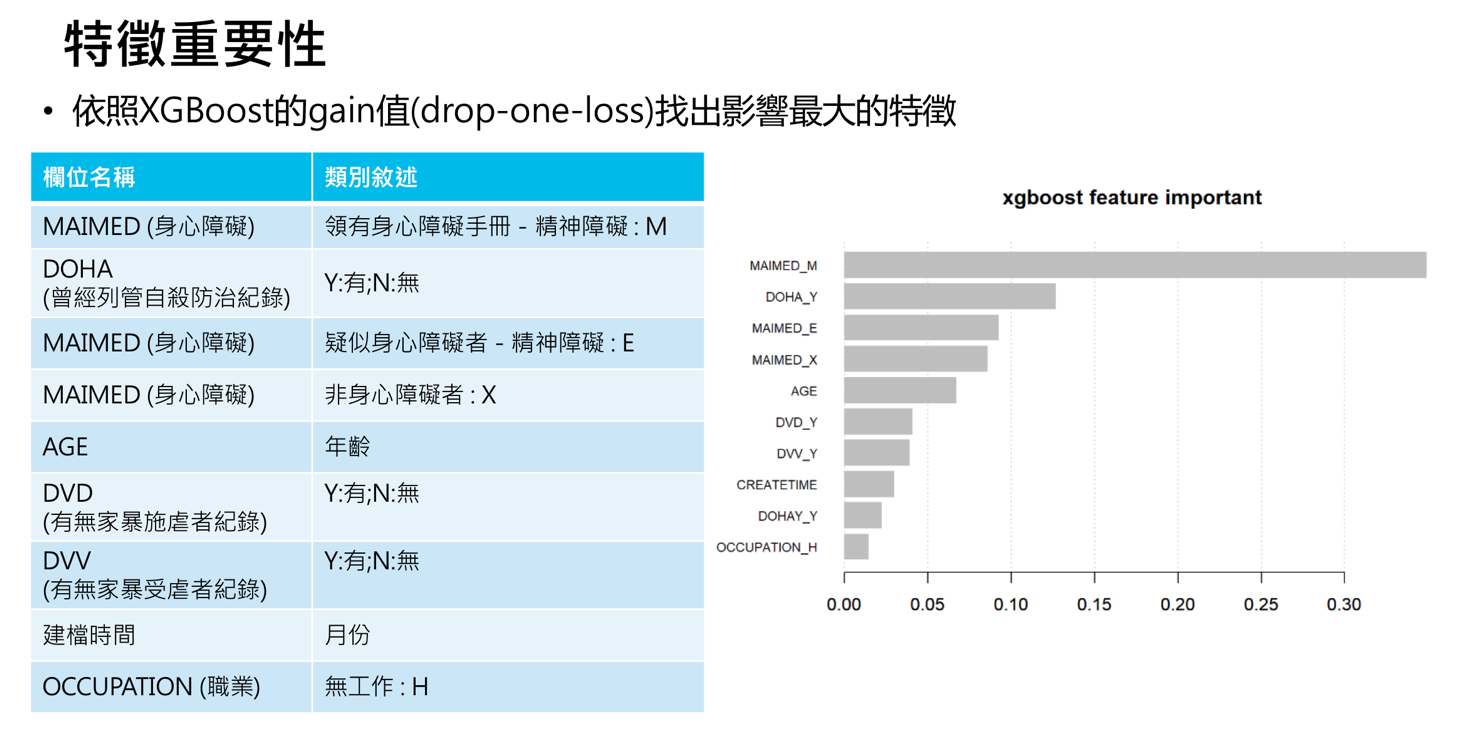
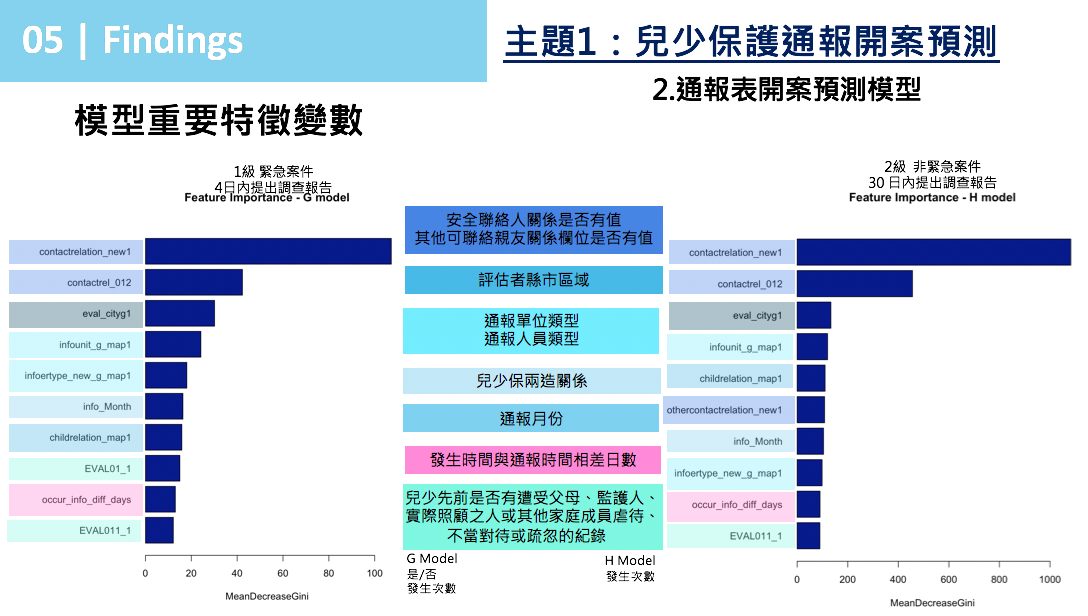 圖 8 模型重要特徵變數
圖 8 模型重要特徵變數
模型重要特徵變數以下述為主(見圖 8):
- 安全聯絡人關係是否有值
- 其他可聯絡親友關係欄位是否有值
- 評估者縣市區域(依縣市地理區域grouping後)
- 通報單位類型
- 通報人員類型
- 兒少保兩造關係
- 通報月份
- 發生時間與通報時間相差日數
- 兒少先前是否遭受父母、監護人、實際照顧者或其他家庭成員虐待、不當對待或疏忽的紀錄
G模型評估
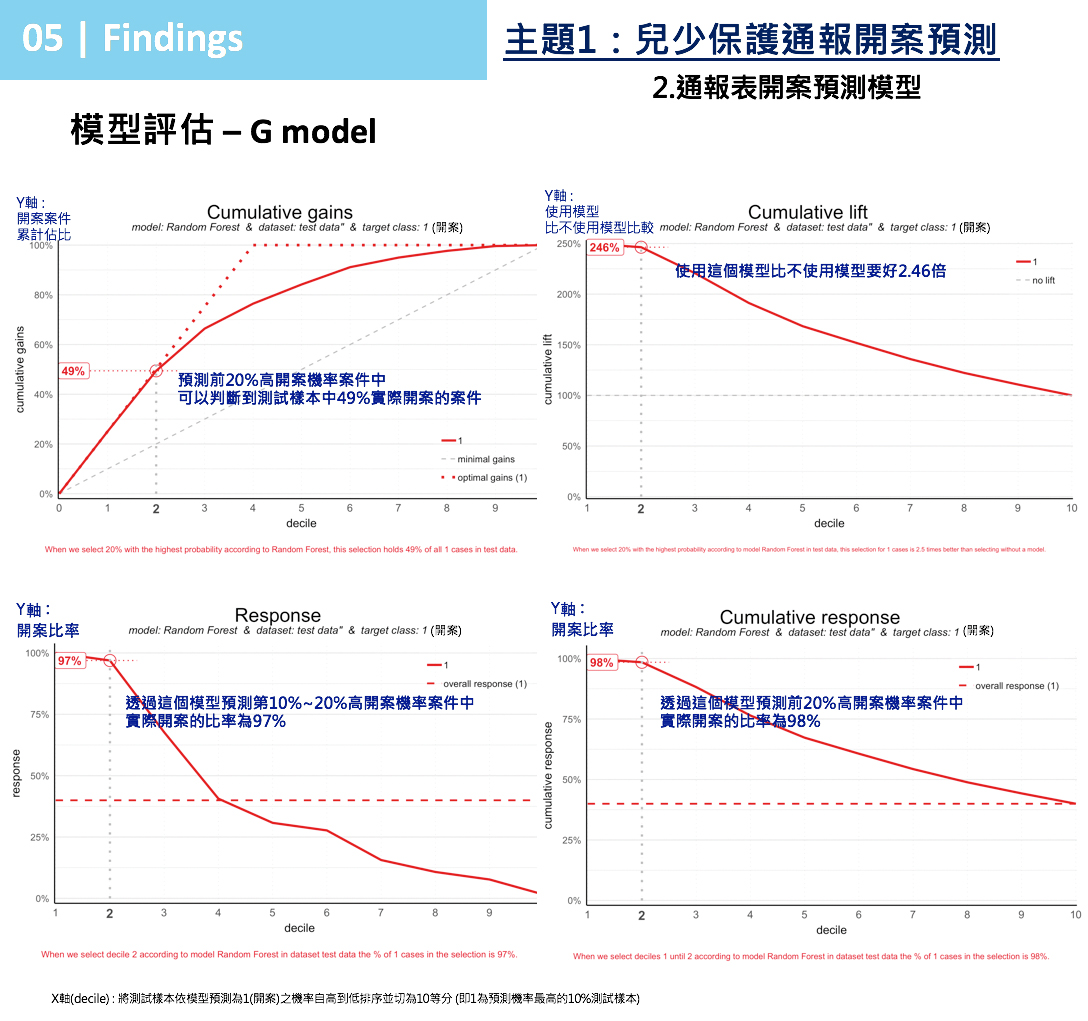 圖 9 G模型評估
圖 9 G模型評估
- Cumulative Gains Plot:
取預測前20%高開案機率案件中,此模型可判斷到測試樣本中49%實際有開案案件。
- Cumulative Lift Plot:
取預測前20%高開案機率案件優先進行,比完全不使用這個模型隨機挑選順序,參考模型預測會比不使用模型要好2.46倍。
- Cumulative Response Plot:
取預測前20%高開案機率案件優先進行,前20%案件的實際開案比率高達98%。
也就是1000個案件用G模型預測後,在原本實際410件開案案件中,G模型用機率排序最高前200個案件,可抓到49%的實際開案者,因此G模型在Cumulative Response前20%開案比率將近100%。
H模型評估
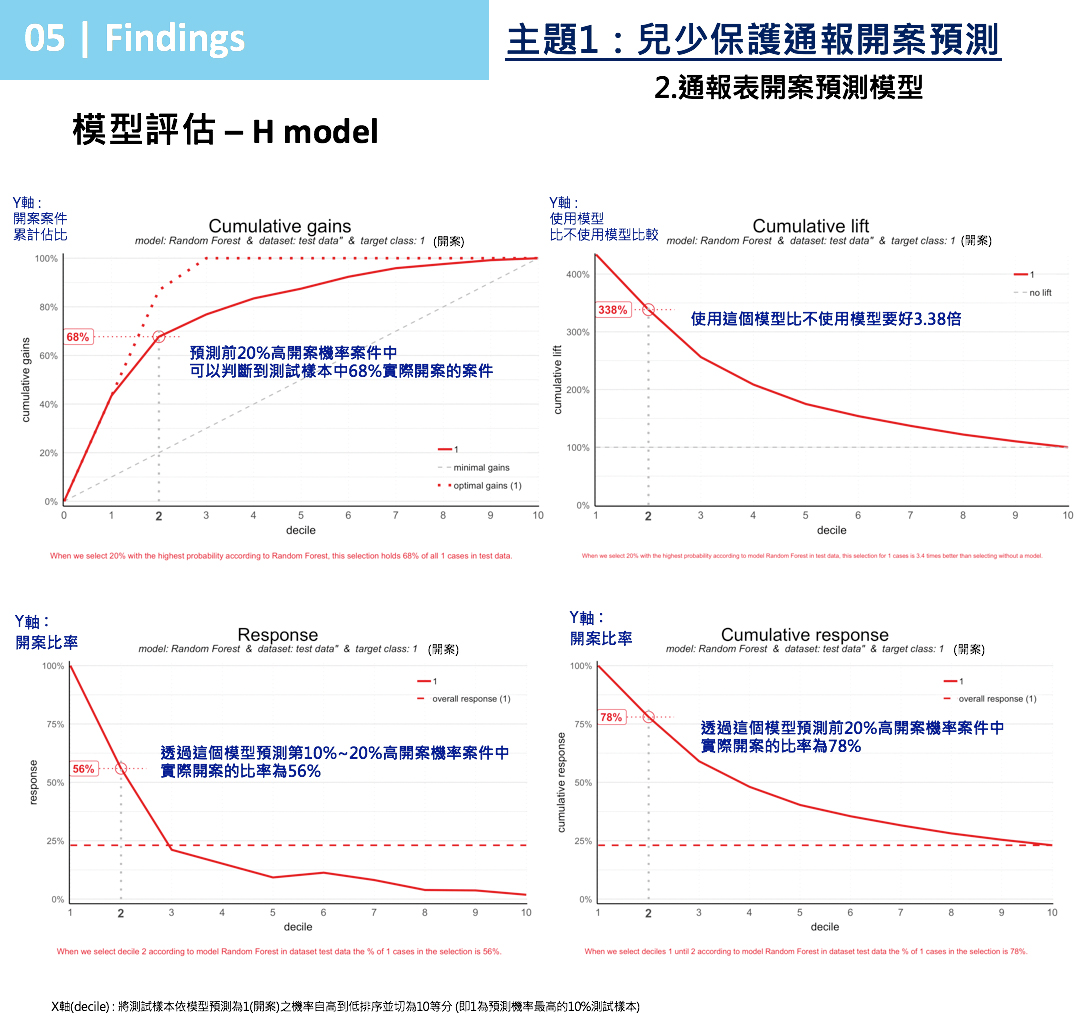 圖 10 H模型評估
圖 10 H模型評估
- Cumulative Gains Plot:
取預測前20%高開案機率案件中,此模型可判斷到測試樣本中68%實際有開案案件。
- Cumulative Lift Plot:
取預測前20%高開案機率案件優先進行,比完全不使用這個模型隨機挑選順序,參考模型預測會比不使用模型要好3.38倍。
- Cumulative Response Plot:
取預測前20%高開案機率案件優先進行,前20%案件的實際開案比率高達78%。
也就是1000個案件用H模型預測後,在原本實際230件開案案件中,H模型用機率排序最高前200個案件,可抓到68%的實際開案者,因此H模型在Cumulative Response前20%開案比率78%。

3. 通報表案情陳述NLP
斷詞有Jieba和CKIP中研院斷詞兩個選項,選擇Jieba除了評價較好之外,CKIP申請後過一段時間即失效比較麻煩。
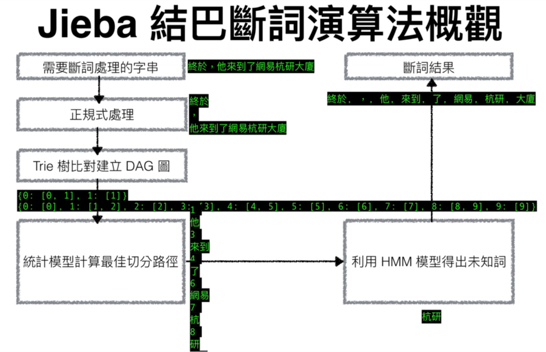
圖 11 Jieba 結巴斷詞演算法概觀
斷詞系統要斷的好最重要的是字典的完整度以及HMM模型能否發現好的新詞,我們的作法是一開始先使用HMM模型來發現新詞,透過後面的TF-IDF算法來校正辭典,再把HMM關閉重新斷詞,要把HMM關閉重新斷詞的原因是,也有可能干擾斷詞本身,使得校正在辭典後的新詞或舊有的詞被斷錯。
TF是詞頻,IDF是逆文檔頻率,TF是單純的詞頻佔比,IDF白話文來說就是,越多文章有這個字,那IDF係數越小,成反比,用這種方式來找到獨特的字,缺點是詞頻(TF)很高但是在其他文章出現很少的字(IDF)也不一定真正是獨特的字,可能存在特例,所以依然要檢查TF-IDF特高以及TF-IDF特低的值,除此之外由於TF-IDF只能代表「某個字在某個文章內的重要性」,不能代表對於所有文章的重要性,所以還有進一步做處理。在分群前先透過Word2Vec算出每個詞的詞向量,上下文相近的單字他們的詞向量會相近,舉例來說,責打之於口角以及威脅之於要求,透過詞向量相近的特性下去分群,自然意思相近的詞會在同一群內,以方便後面把分群的各個群當features的動作
以下是各群的文字雲,字的大小代表TF-IDF的大小。可以看到圖 12跟就醫和急診的TF-IDF特別高,也接近這個群的主題。
 圖 12
圖 12

圖 13
圖 13 這四群跟身邊環境影響有關,以及有沒有單位介入這類資訊都可以從這些群看出來,證明這些群確實可以代表某些案子的情形,如果就醫急診特別多,那可能是被家暴的很嚴重,如果親戚周圍環境的詞較少就代表缺乏家內外都缺乏支持。
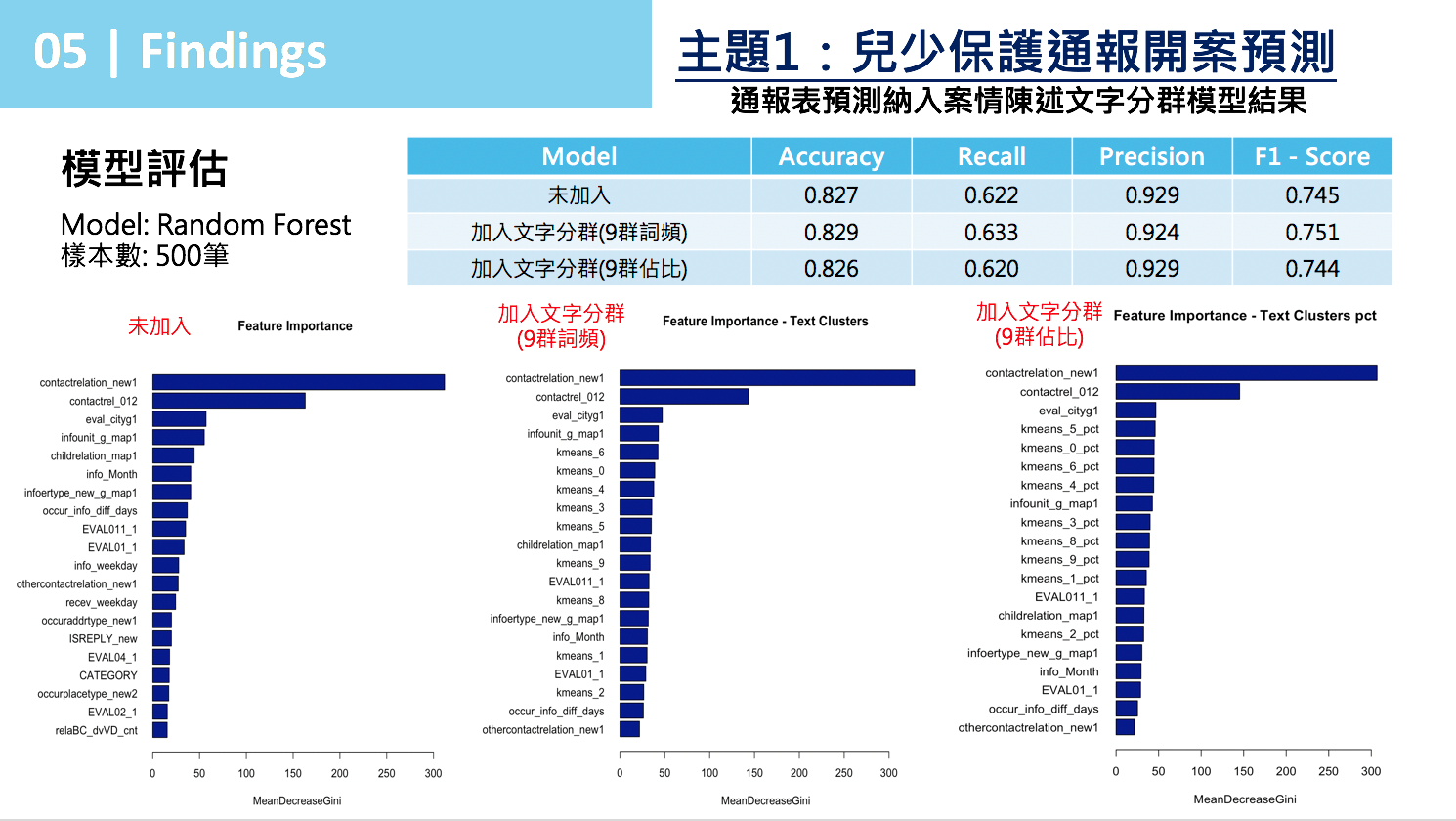
圖 14
在通報表中有一項案情陳述,屬於文字敘述的內容。透過500筆已去個資資訊之案件,進行文字斷詞、分群,結合文字分群納入模型開發,比較未加入文字分群、加入文字分群(9群詞頻)、文字分群(9群佔比)個別開發模型。
圖 14 顯示模型評估Accuracy、Recall、Precision差異性不大,文字分群9個變數皆進入前20大重要特徵變數,甚至前10大重要特徵變數文字分群可進入5~6個。
即案情陳述的文字記錄內容,透過自然語言處理技術(NLP),萃取有價值的意涵,在預測開案與否的模型上,能取代某些通報表欄位資訊。
主題2:共案特徵預測及訪視優先次序分析
1. 緣由
兒少保護開案案件中,透過調查報告找出與「保護司與心口司共同列管案件(共案)」特徵類似之案件,但未有心理衛生社工介入服務(未納入共訪機制),預先提示兒少保社工提高服務密度及敏感度。
2. 資料
- 使用2016和2017年一類被害人父母調查報告資料進行分析:
- 目標:找出應提高服務敏感度之案件(與共案特徵相似之案件)。
- 目標特徵:兒少保案件應進行共案管理者。
- 特徵:建檔月份、年齡、與案主關係、教育程度、 國籍別、現住地址(縣市) 、是否與案主同住、居住狀況、身心障礙、婚姻狀況、職業、親子關係、性別、自殺紀錄、家暴施虐紀錄、家暴受虐紀錄。
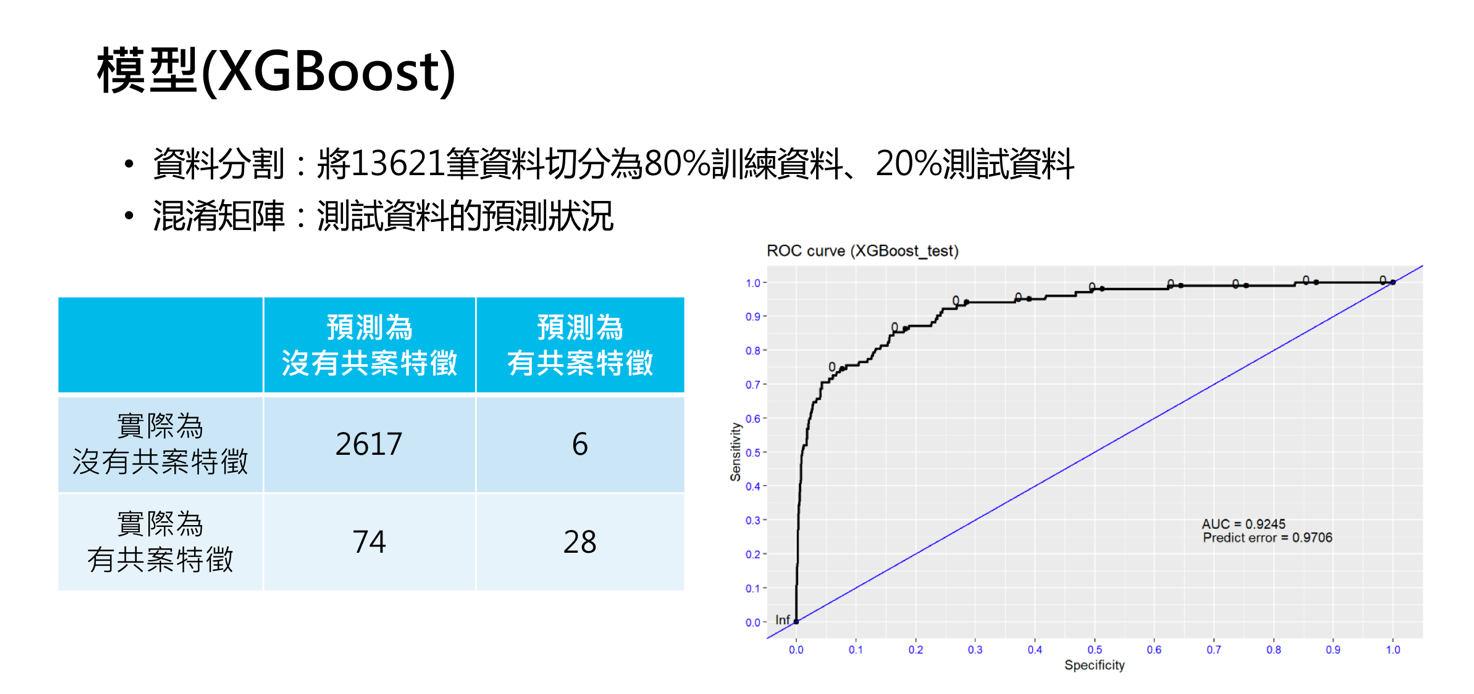
3. 成效
- 使用XGBoost模型進行建模,找到最具影響力的10個變數可以供往後社工在拿到通報表可以快速篩選出具共案特徵的案件,並且透過模型解釋變數對個案的影響。
- 透過模型的預測能力,在未來可提供雙邊的社工安排案件訪視優先順序的輔助參考,特別是在有限資源且案件數過多的狀況,可以在有限時間內做更有效率之安排。
四、結論
主題1:兒少保護通報開案預測
未來可作為兒少保社工安排案件調查順序之輔助參考,特別在非緊急案件(H model),預期提升3.4倍效率,紓解非緊急案件處理順序問題。
主題2:共案特徵預測及訪視優先次序分析
協助兒少保社工在處遇階段,利用共案特徵預測,找到潛在高關注個案,及其影響因子,提高服務密度與敏感度。
五、參考資料
- 尹欣如(2013)。兒童虐待事件中社工風險評估與成案決策之相關性探究──以桃園縣家暴中心為例。臺灣大學社會工作學研究所,台北市。
- Jolley, J. M. (2012). Applying neural network models to predict recurrent maltreatment in child welfare cases with static and dynamic risk factors. Electronic Theses and Dissertations.
- English, D. J., & Pecora, P. J. (1994). Risk assessment as a practice method in child protective services. Child Welfare, 73(5), 451.
- Wald, M. S., & Woolverton, M. (1990). Risk assessment: The emperor’s new clothes? Child Welfare, 69(6), 483-511.
- Sledjeski, E. M., Dierker, L. C., Brigham, R., & Breslin, E. (2008). The use of risk assessment to predict recurrent maltreatment: A classification and regression tree analysis (CART). Prevention Science, 9(1), 28–37.
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021