
本次專案以 111年度累積跨網絡會議案件資料為基礎,透過各種方法探索現行作業填寫方式之有效性、網絡資源介入機制運行狀況、以及檢定驗證各類指標、評估工具對於會議討論之幫助程度,並試圖提出更有效率的資料登打及收集流程。 本次亦進行了知識本體的建構,嘗試將兒少保護跨網絡合作會議運作及相關會議資料轉化為機器可讀的知識,以便未來進行深入分析;同時透過本體建構進行相關概念釐清,並初步探討了如何在資料面落實「強化社會安全網第二期計畫」中所提出從「以案主為中心」朝向「以家庭為中心、社區為基礎」服務模式轉變的可能性。
Fellows:簡毅慧、蘇彥庭、李俊穎、江泓德
Mentor:陳潔寧
Project Partner:不當黨產處理委員會
早期史料多以紙本或影像檔案儲存,造成史料研究難以有效整合有關聯的資訊。委員會的研究員們指出既有的史料雖然有豐富的文字訊息,但是在文章間的關聯性探索仍然得仰賴研究員們各自閱讀後的經驗積累,這使得研究成果不易橫向串連或者傳承。然而,文字探勘技術在這樣的手寫歷史文件分析中仍屬不易,我們將重心擺在已經轉為文字檔的史料故事,建立搜尋優化的支援系統、對外呈現友善簡潔的知識視窗,包含:文章推薦系統、社會網絡分析與數位專題等應用呈現。
首先,我們利用中央研究院中文詞知識庫小組(Chinese Knowledge and Information Processing, CKIP)的實體辨識技術進行文章斷詞與詞性的辨別,並且與研究員們合作,建立專屬不當黨產委員會的字典,這本字典有助於辨別文章內字詞的精準度,同時,我們也開放字典的增添,保留後續新增文章時的彈性調整。有賴於前述的基礎,我們建構文章間的字詞詞向量矩陣,並計算文章間的相關性,提供以文找文的文章推薦系統。
其次,文章內提及的人、機構也蘊含著一定的關聯性,但是在既有的探索中,未能系統性地釐清人物之間或者機構之間在特定主題下的關係結構。社會網絡分析(Social Network Analysis, SNA)既是一種以關係為核心的分析技術也是一種資料視覺化的工具。我們利用前述的字典建立人物與機構清單,爬梳這些名單在文章庫中出現的情況,共同出現在同一篇文章即視為有關係/連結,藉此繪製出社會網絡圖。此外,我們將節點進行分群,使得圖形大小得以反應該節點的重要性;而連結的強弱也利用關係線的粗細進行呈現,這些使得資料視覺化的過程中富含充裕的資訊。為了使網絡分析與文章庫有效地結合,我們也提供節點、連結對應的文章清單,讓研究員們在探索網絡關係時得以便捷地閱讀相關文章。
針對對外的友善簡潔知識視窗,我們採用數位專題呈現研究員們的史料研究成果,將數筆主題性的歷史文件轉化為生動且具互動的閱讀頁面。在與研究員們的討論過程中,我們自身也更加認識當時的歷史,而為了推廣這些知識,在專題頁面中圖、文併呈,使得故事深刻地被記憶而不乏味,我們也使用地圖跟時間軸呈現不當黨產的歷史變化與所有權流向,同時也結合委員會的紀錄影片讓讀者有不同層次的閱聽經驗。
完整的專案成果簡報檔。
___
延伸資料:
透過時間、空間、詞頻分析、史料間關係等面向出發建構數位化工具,協助研究員能夠更快速地從史料文章中,分析出人或組織之間的關係。
安裝說明:https://github.com/SuYenTing/d4sg_cipas_project
針對數位化敘事進行改善,提升研究成果閱讀、視覺化、可讀性等改善。
網頁成品:https://yihuai0806.github.io/cipas/index.html
\

Fellows:廖立文、陳薇亘、黃鼎豪、鄭雅憶
Mentor:陳潔寧
Project Partner:臺北市家庭暴力暨性侵害防治中心
家防中心保護性社工於外勤執行受暴者及行為人之訪視、庇護及安置服務時,存在各種人身安全風險,也許是被打、被言語侮辱、被威脅。社工出訪前會先閱讀系統中的個案相關紀錄,然而紀錄龐雜且繁瑣,每次的訪視風險都需要靠個人大量閱讀並綜合過往經驗才能判斷風險高低。
中心為了提高人為判斷精準度,設計外勤風險檢測指標,要求社工出勤前須填寫,並定期滾動修正,透過事先掌握風險,進行預防。在累積數年資料後,希望能透過資料進行填寫行為分析、結果比對及優化表單,從中發展出風險因應策略,建立循證治理的工作流程。
透過服務流程工作坊盤點出社工外勤挑戰
D4SG 資料英雄為了了解社工大量閱讀的個案資料及獲取資訊的流程、如何將資料轉化為所需資訊,我們在 110 年 11 月 17 日於家防中心辦理服務流程討論工作坊,參與人員包含家防中心綜規組、承保組、專線組、兒少組與性保組 16 位,以及本案資料英雄 6 位,共 22 位。依組別編列為四組,於工作坊過程中,皆有資料領域、服務設計領域之資料英雄一同參與討論。
本次工作坊透過情境將相關利害關係人以及所遇問題進行盤點,建構社工接案到受暴通報之程序。最後釐清步驟中的數據細項與來源,並思考何以透過數據優化現有的任務流程,期以避免社工出訪時的風險。綜合各組提到的執行挑戰如下:
1. 社工對於風險意識高低不同
新手經驗薄弱,對事件之風險敏感度較低;資深者則易低估風險。而現行系統中尚無客觀風險評估指示,可作為判斷風險之參考。
2. 風險釐清條件不足
相關通報資訊不足,於時效條件下,導致難以釐清風險狀況。潛在人生安全評估項目(如:環境衛生狀況、是否有危險寵物等),無法取得相關資料,以致難以提前規劃與預防。
3. 訪視時效與資料權限限制
系統需於網域中才可登打,尚不能透過行動載具使用。填寫內容項目不夠精簡或無自動帶入之功能,導致行政作業繁複。
4. 資料視覺化及預測的目的及目標理解不足
現行以紙本及簡易數字加總統計值進行管理,對於如何紀錄資料達到數據視覺化、風險預測及循證治理方式理解及經驗較少。
概念驗證 POC
本次資料科學家及服務設計學者等資料英雄參與上段詳列了家防中心自評及各組討論後的結果,其中的調整涉及跨部門協力、系統設計、管理手段上讓回報更彈性、風險預警共識等。基於近期中心即將做系統改版以及中心長期累積的出勤前資料,資料英雄提出概念驗證及實作。
一、系統設計概念
針對訪視前、後,我們分別提出系統規劃與系統優化的建議。
訪視前

Fellows:王政雲、張沛詠、曾仲毅、楊寓鈞
Mentor:劉嘉凱
Project Partner:臺北市政府工務局採購科
問題描述
每個月稽核委員完成現場查察後須依限撰寫稽核報告,將查證結果以三段式寫法呈現,分別為「法規依據」、「違規事證」及「改善建議」,並送交稽核小組查核員同仁進行校稿彙整。當採購稽核委員在系統輸入缺失意見及其援引法規時,容易誤用法規,因此台北市查核員經常需要花費大量心力協助調整為正確法規。
希望藉由「法規推薦」的方式,在委員輸入缺失意見時,自動推薦相關的法規,降低錯誤使用法規的頻率,提升委員稽核報告之撰寫效能與品質。
分析方法
一、流程概述
依據市府提供資料進行討論,補足相關資料後進行推薦系統的設計,並重複進行準確率評估和調整模型。
(一)、資料蒐集
除了北市府提供的訓練資料和測試資料外,我們依據建模需求,藉由網路爬蟲蒐集相關輔助資料。
資料清單
訓練資料:200801至202008缺失類型(法規分段例),法規的部分有23,228筆。
測試資料:原始意見及定稿意見彙整表_v3,共49筆。原始意見為委員原本輸入的文字,定稿意見則為稽核同仁修改後的版本,用詞較為一致。
輔助資料 – 移除法規:法令依據/事實/改進建議分段,法規跟錯誤態樣各50筆。
輔助資料 – 移除法規:法令依據/事實/改進建議分段,法規跟錯誤態樣各50筆。
輔助資料 – 字典:法規字典、法規切分字典。
(二)、資料前處理
對原始資料和另外蒐集的輔助資料進行資料前處理。
以下為處理步驟:
(三)、模型建立及模型評估
進行資料前處理後,我們開始進行模型配適以及評估。
反覆使用不同模型進行訓練,再比對測試結果準確度,找到最高準確度的模型。
二、探索式資料分析(EDA)
在訓練資料的筆數分佈上,政府採購法的占比最高,將近三成,樣本的分佈不均可能會有兩個影響,一方面是樣本足夠的類別會得到較多的資訊,推薦成果較為準確,部分過少樣本可能因為資料不足而無法取得充足的資訊,而成效較差。
訓練資料的法規名稱的筆數分佈
測試資料集上,與訓練資料筆數分佈較為不同的有


Fellows:林祁衡、蕭玉資、胡文馨、徐紹婷、李佳昇、余佑駿
Mentor:陳潔寧、詹欣諭
Project Manager:巫坤達
Project Partner:臺北市政府社會局社會救助科
臺北市政府社會局與伊甸社會福利基金會合作進行專案,協助經濟弱勢者重回勞動市場。
社會局每年會從經濟弱勢的低收入戶、中低收入戶、從事代賑工的清寒戶中,選取目前沒有就業的經濟弱勢者為待輔導就業對象,委託伊甸基金會進行輔導。伊甸基金會於獲得經濟弱勢者名單後,即進行聯絡與訪談,透過訪談內容判定個案是否應「開案」繼續進行就業輔導。
開案後,伊甸基金會會以個別化的服務模式,針對個人就業阻礙與需求提供就業輔導,包含職業諮詢、重返職場信心建立、開辦職訓課程等,持續輔導至個案穩定就業或社會局評估可停止追蹤。當個案穩定就業重返職場,即達到專案目的「幫助經濟弱勢者脫離貧窮」。
痛點與解方
然而,社會局與伊甸基金會在過去幾年的合作上遇到了瓶頸:篩選出的經濟弱勢者名單開案率不高;即使開案,依照開案數量,最後脫貧的比例也不高。因此,社會局與伊甸基金會希望透過各項服務紀錄,優化服務流程及作法,以提升開案率與就業意願。
本次資料英雄將處理以下兩個議題:
A. 優化推薦至伊甸基金會名單,提高成功開案率
B. 找出容易成功就業的個案特性,提高社工的工作效率
資料英雄根據資料分析流程先進行需求訪談和資料初探,實際了解工作流程細項與資源,再針對兩個議題規劃不同的資料分析策略。
議題A:優化社會局推薦至伊甸基金會名單,提高成功開案率
一、用關聯規則萃取重要變數
先利用關聯規則萃取出重要變數,社會局的資料變項有三種類型,人口變項包含性別、年齡、教育程度等變項;家庭因素包含家中0-6歲小孩人口數、7-12歲小孩人口數、65歲以上長者人口數等變項;收入相關則包含收入等級、補助金額等變項。
實作關聯規則是採用R語言的arules套件,參數設定包含最小規則長度為3(minlen=3)、規則所篩選出的最小樣本佔比為1%(support=0.01)以及樣本的最小開案率為8%(condifence=0.08)。將結果以Lift排序,以排序第一的規則為例,輸出如下表。
對於「教育程度為高中職、家中補助金額低於36K、沒有13-15歲小孩、沒有65歲以上長者」這個族群而言,佔訓練資料中的1.9%,開案率為25%,是訓練資料8%開案率的2.79倍。
根據排序前30筆規則,歸納出以下兩種族群具有比較高的開案率:
1. 教育程度為高中職且補助金額低於36K
2. 教育程度為高中職、收入為低收等級且沒有不動產的紀錄
除此之外,其他與開案成功相關的重要變項包含女性、無0-6歲小孩、無13-18歲小孩以及無65歲以上長者。
二、用廣義線性模型優化社會局推薦名單
1. 動機與目的

錄取提案
家事訴訟:以歷史的判決看外配是否受到法律差異對待(法律扶助基金會)
參照內政部移民署網站統計資料,截至2018年底,外裔或外籍配偶人數已達近18萬人,又每年約1萬多人登記結婚、亦有近5千人離,是以對於非在台灣生長,對於台灣文化陌生,更不諳本國語言及法律之外籍配偶,其在家事訴訟程序中是否受差異之對待,其成因為何,現有之法律扶助律師是否已提供適切之服務等,皆為此次專案所欲探詢之問題。
▌關鍵詞:法院判決、文字探勘
有限社工人力資源解決高危機個案(桃園市政府家庭暴力暨性侵害防治中心)
家防中心針對家暴被害人及其家庭提供服務,乃為重要業務內容之一。桃園市平均一年約1萬餘件之家暴通報案件,如何在有限人力、資源前提下,針對具高度生命危機議題可能生的案件中,在定期網絡合作中共同找出當中的高高危機個案,立即並優先介入係顯得重要及必要。
▌關鍵詞:高風險家庭、風險預測、危險因子
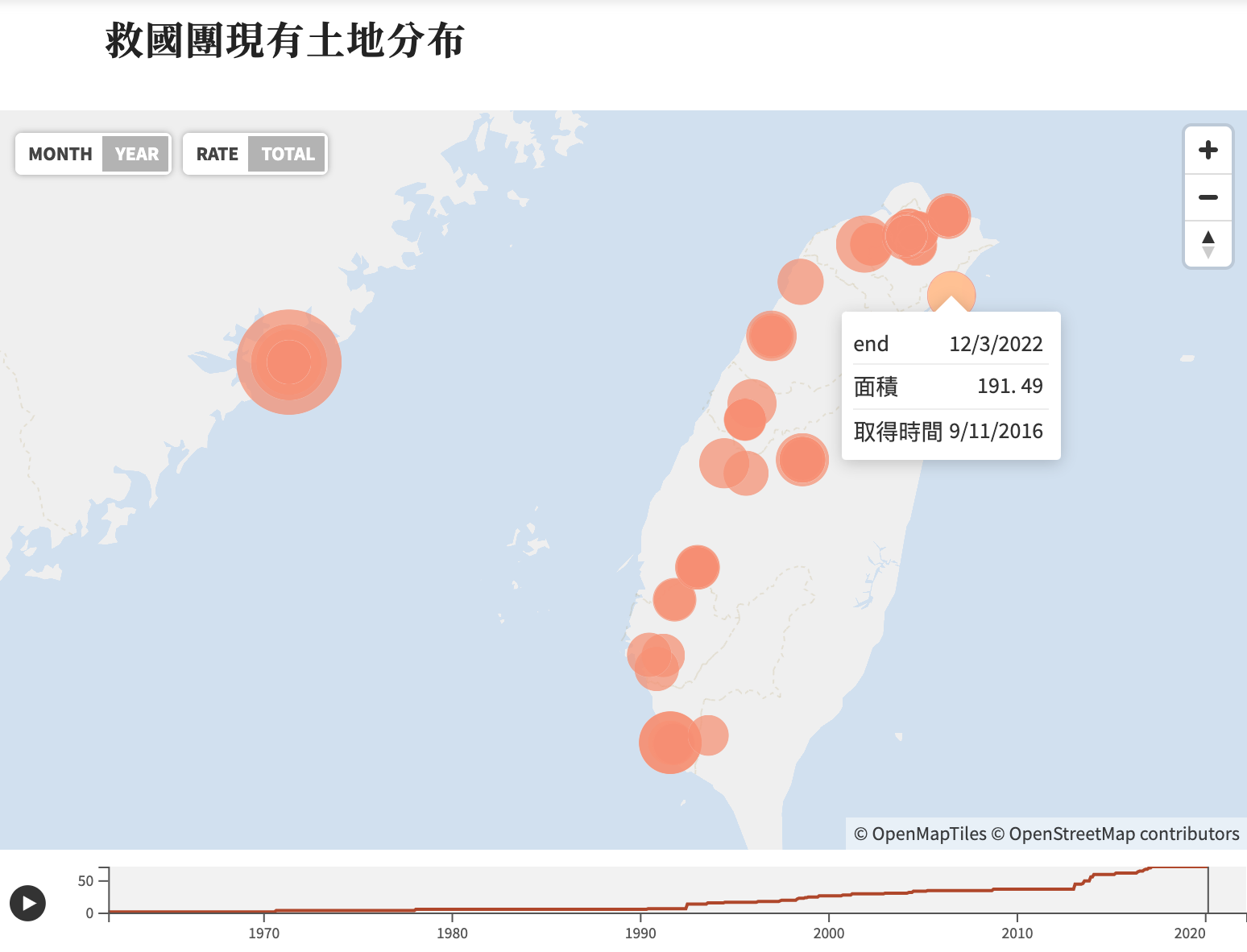
智慧防洪,韌性城市(臺北市政府工務局大地工程處)
近期,午後豪大雨造成排水系統瞬間過載無法負荷,成為水災或坡地崩塌之主要成因,集中降雨以既有的水文學說而言,解決方式通常是投入更多的錢去整治,做出更高的防洪標準(有錢的縣市),或是乾脆將易淹水區域的居民遷移至別處安置(省錢的做法);但是近年來資料科學的進步,是否可以透過資料探索來摸索出一個彈性防洪的方法,讓有限的資源做出更好的利用(比如以50年防洪標準的設施搭配其他防洪手段,讓防洪標準可以等同75年水準等),即是我們想要探討的目標。
▌關鍵詞:防洪、韌性城市
錄取英雄
石O蓁、江O矩、吳O展、吳O萱、李O杰、李O雲、李O萱、李O臻、林O逵、邱O琪、
邵O磊、姜O文、姜O安、張O偉、張O婷、張O懋、陳O廷、黃O淳、黃O雅、葉O安、
廖O程、蔡O涵、蕭O哲、謝O翰。
本次資料英雄計畫的主題包含法律正義丶社會安全與災害防治。
每個提案都將派遣專家與提案單位進行資料盤點、問題聚焦、預期成果評估等討論,再根據預期成果的社會影響力、資料成熟度、時限內可完成程度、經驗可複製性、以及主管是否積極支持讓成果能確實導入組織運作等面向進行審查,以決定錄取名單。
關於資料英雄的錄取標準,則是以完成專案主題的技能需求為基準,由負責專案的指導顧問進行選秀,根據個人技能與興趣分配。
本期共錄取 24 位資料英雄 。將於 2018/12/17 (一) 寄發錄取通知,若屆時您沒有收到信件請來信 service@dsp.im,謝謝。
Fellows:陳姿君、張赫麟、張家豪、藍浩、潘怡均、吳奇倫、吳又建、林瑜軒
Mentor:謝宗震、楊思
Project Manager:陳映竹
Project Partner:衛生福利部保護服務司
通過文獻梳理,我們發現「風險評估」在兒少保領域的應用在20世紀90年代就已經普及(English & Pecora, 1994),在現如今依然是主要的評估工具。在學術領域,兒少保領域的「風險評估」可被定義為「評估某個既定的(通常是父/母)人在未來可能傷害兒童的一個過程」(Wald & Woolverton, 1990)。據已有研究,通過整理各種主要的風險評估工具,其共同考量的因素不超過三大類別的範圍:兒童特徵或受虐情況,父母特質與家庭環境(尹欣如,2013)。
大數據應用於兒少保領域的風險評估在其他國家早已有所應用,美國聖路易斯華盛頓大學的Jolley(2012)曾用神經網絡模型將風險因素分為靜態因素和動態因素,來預測兒童遭受不良對待的復發。也有學者通過分類和回歸樹分析來對兒童遭受不良對待的復發來進行預測,發現對高風險組有更好的預測力(Sledjeski, Dierker, Brigham & Breslin, 2008)。
一、研究資料與主題
圖 1
主題1:兒少保護通報開案預測
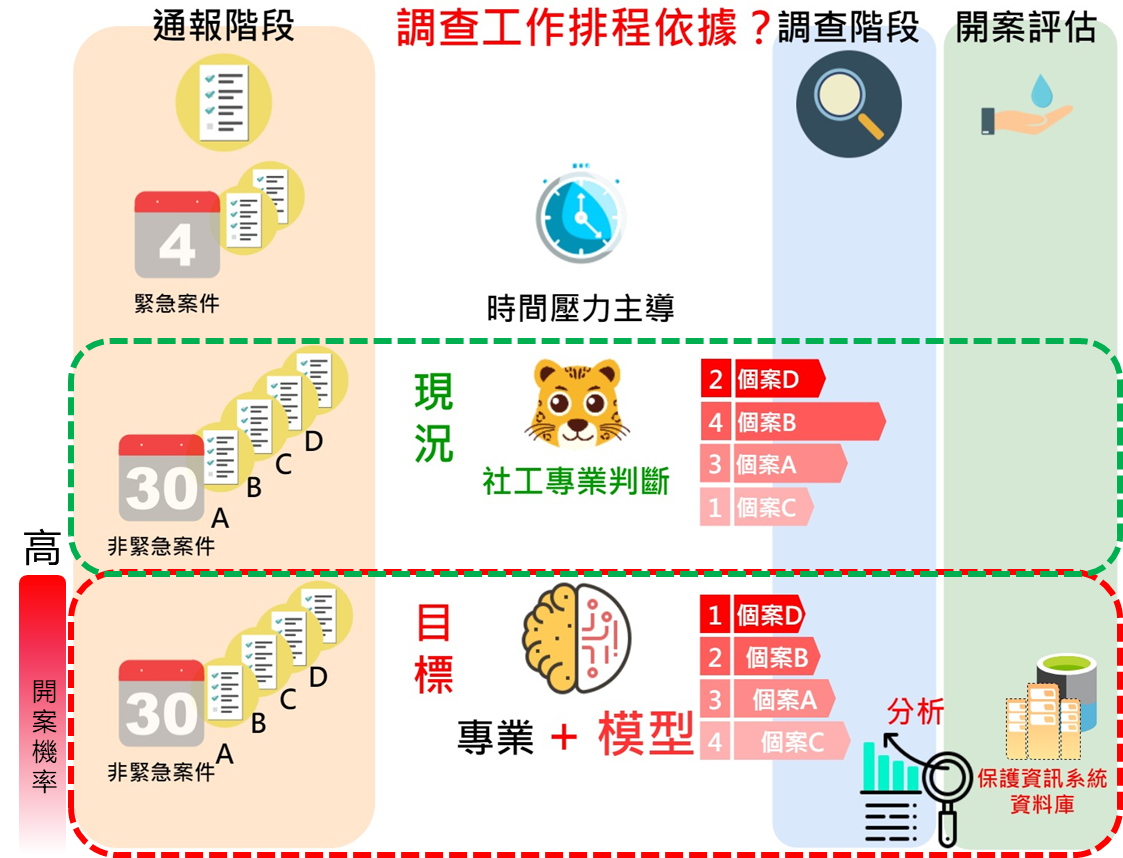
透過通報表資訊預測該案開案與否,提供兒少保社工進入調查階段前案件優先順序參考。分析使用2017年一類案件通報表及關係人基本資料,包含最終開案及未開案案件,共20,165筆。
從通報過渡到調查階段,大量的非緊急案件,現況仰賴社工專業判斷。我們目標是社工不僅是面對當下的通報案件、自身專業判斷,透過分析資料庫中歷史通報案件,建構開案預測模型輔助社工,綜合自身專業與模型結果資訊成為工作排程依據。
圖 2
主題2:共案特徵預測及訪視優先次序分析
兒少保護開案案件中,透過調查報告找出與「保護司與心口司共同列管案件(共案)」特徵類似,但未有心理衛生社工介入服務(未納入共訪機制)之案件,預先提示兒少保社工提高服務密度及敏感度。分析使用2016和2017年一類案件被害人父母調查報告資料,篩選出最終開案的案件,共13,621筆。
進到服務階段,實務經驗告訴我們保護司、心口司兩個單位共同列管個案,必須有較高服務密度。也已建立保護司兒少保社工、心口司心衛社工的「共案共訪」機制。相對的,非共同列管案件就沒有心衛社工介入服務。即便未納入共訪機制的個案,透過共案特徵預測,預先提示兒少保社工提高服務密度及敏感度,仍可提供綿密的服務。
二、分析手法
主題1:兒少保護通報開案預測模型
使用關聯分析找出通報表填報項目選項中影響開案的重要因素。並透過通報表結構化資料及案情陳述非結構化文字資料,結合自然語言處理(NLP)與Random Forest隨機森林技術建立開案預測模型。
