黨產會專案文本分析系統
Mentor:陳潔寧
Project Partner:不當黨產處理委員會
早期史料多以紙本或影像檔案儲存,造成史料研究難以有效整合有關聯的資訊。委員會的研究員們指出既有的史料雖然有豐富的文字訊息,但是在文章間的關聯性探索仍然得仰賴研究員們各自閱讀後的經驗積累,這使得研究成果不易橫向串連或者傳承。然而,文字探勘技術在這樣的手寫歷史文件分析中仍屬不易,我們將重心擺在已經轉為文字檔的史料故事,建立搜尋優化的支援系統、對外呈現友善簡潔的知識視窗,包含:文章推薦系統、社會網絡分析與數位專題等應用呈現。
首先,我們利用中央研究院中文詞知識庫小組(Chinese Knowledge and Information Processing, CKIP)的實體辨識技術進行文章斷詞與詞性的辨別,並且與研究員們合作,建立專屬不當黨產委員會的字典,這本字典有助於辨別文章內字詞的精準度,同時,我們也開放字典的增添,保留後續新增文章時的彈性調整。有賴於前述的基礎,我們建構文章間的字詞詞向量矩陣,並計算文章間的相關性,提供以文找文的文章推薦系統。
其次,文章內提及的人、機構也蘊含著一定的關聯性,但是在既有的探索中,未能系統性地釐清人物之間或者機構之間在特定主題下的關係結構。社會網絡分析(Social Network Analysis, SNA)既是一種以關係為核心的分析技術也是一種資料視覺化的工具。我們利用前述的字典建立人物與機構清單,爬梳這些名單在文章庫中出現的情況,共同出現在同一篇文章即視為有關係/連結,藉此繪製出社會網絡圖。此外,我們將節點進行分群,使得圖形大小得以反應該節點的重要性;而連結的強弱也利用關係線的粗細進行呈現,這些使得資料視覺化的過程中富含充裕的資訊。為了使網絡分析與文章庫有效地結合,我們也提供節點、連結對應的文章清單,讓研究員們在探索網絡關係時得以便捷地閱讀相關文章。
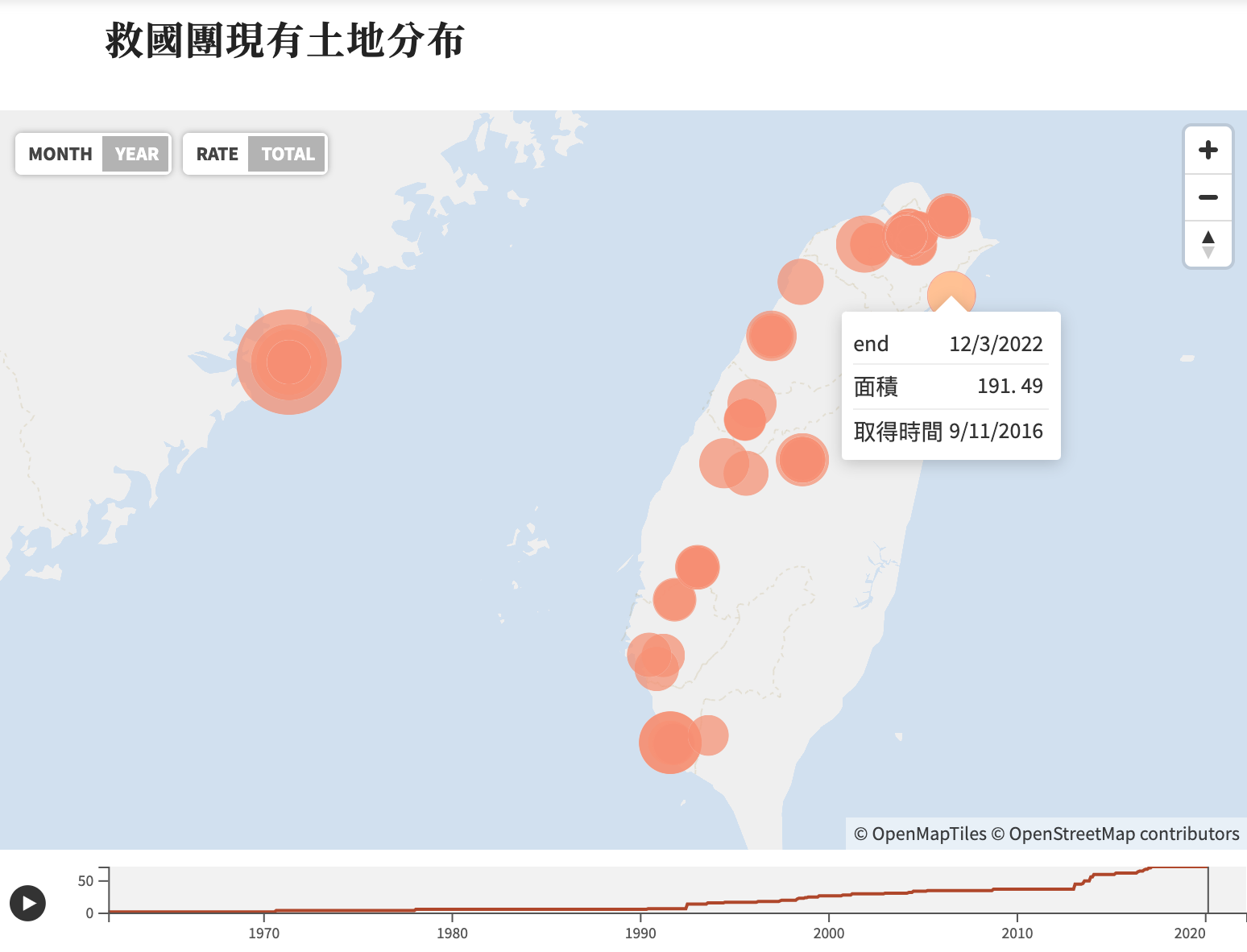
針對對外的友善簡潔知識視窗,我們採用數位專題呈現研究員們的史料研究成果,將數筆主題性的歷史文件轉化為生動且具互動的閱讀頁面。在與研究員們的討論過程中,我們自身也更加認識當時的歷史,而為了推廣這些知識,在專題頁面中圖、文併呈,使得故事深刻地被記憶而不乏味,我們也使用地圖跟時間軸呈現不當黨產的歷史變化與所有權流向,同時也結合委員會的紀錄影片讓讀者有不同層次的閱聽經驗。
完整的專案成果簡報檔。
___
延伸資料:
- 透過時間、空間、詞頻分析、史料間關係等面向出發建構數位化工具,協助研究員能夠更快速地從史料文章中,分析出人或組織之間的關係。
安裝說明:https://github.com/SuYenTing/d4sg_cipas_project
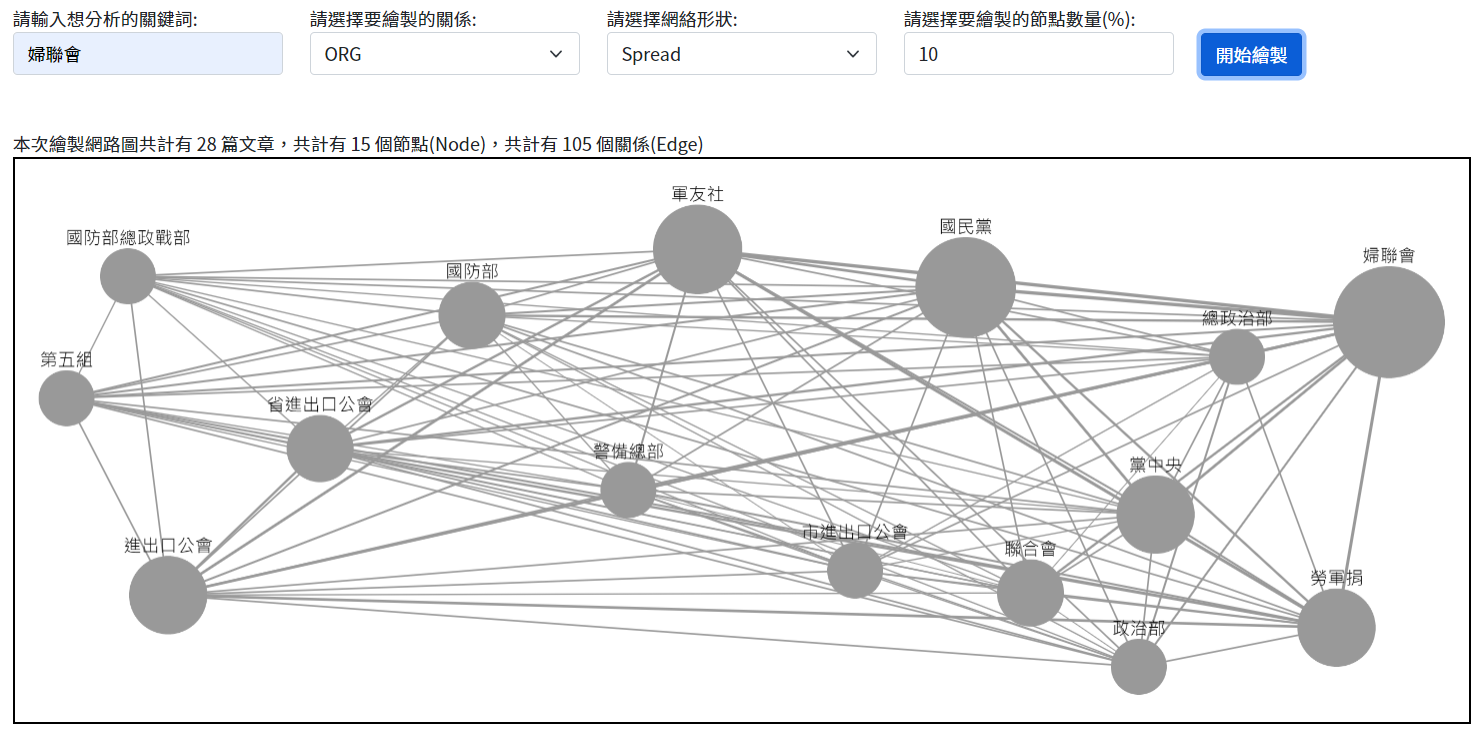
- 針對數位化敘事進行改善,提升研究成果閱讀、視覺化、可讀性等改善。
網頁成品:https://yihuai0806.github.io/cipas/index.html
\