
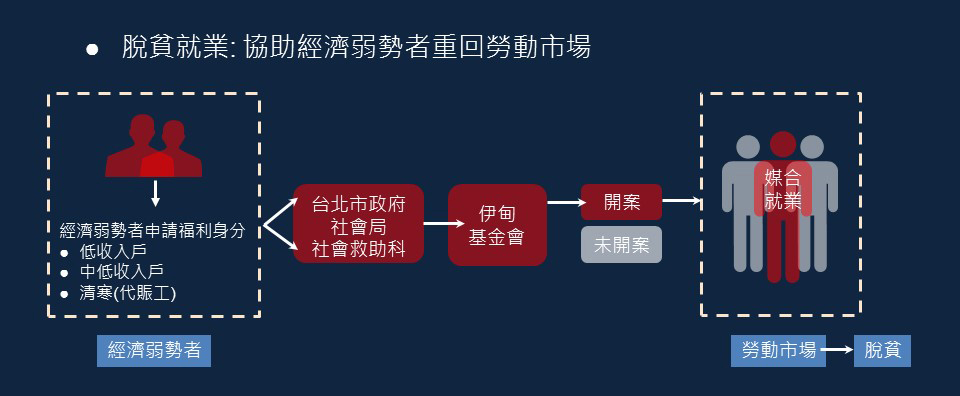
脫貧就業:協助經濟弱勢者重回勞動市場

Mentor:陳潔寧、詹欣諭
Project Manager:巫坤達
Project Partner:臺北市政府社會局社會救助科
臺北市政府社會局與伊甸社會福利基金會合作進行專案,協助經濟弱勢者重回勞動市場。
社會局每年會從經濟弱勢的低收入戶、中低收入戶、從事代賑工的清寒戶中,選取目前沒有就業的經濟弱勢者為待輔導就業對象,委託伊甸基金會進行輔導。伊甸基金會於獲得經濟弱勢者名單後,即進行聯絡與訪談,透過訪談內容判定個案是否應「開案」繼續進行就業輔導。
開案後,伊甸基金會會以個別化的服務模式,針對個人就業阻礙與需求提供就業輔導,包含職業諮詢、重返職場信心建立、開辦職訓課程等,持續輔導至個案穩定就業或社會局評估可停止追蹤。當個案穩定就業重返職場,即達到專案目的「幫助經濟弱勢者脫離貧窮」。
痛點與解方
然而,社會局與伊甸基金會在過去幾年的合作上遇到了瓶頸:篩選出的經濟弱勢者名單開案率不高;即使開案,依照開案數量,最後脫貧的比例也不高。因此,社會局與伊甸基金會希望透過各項服務紀錄,優化服務流程及作法,以提升開案率與就業意願。
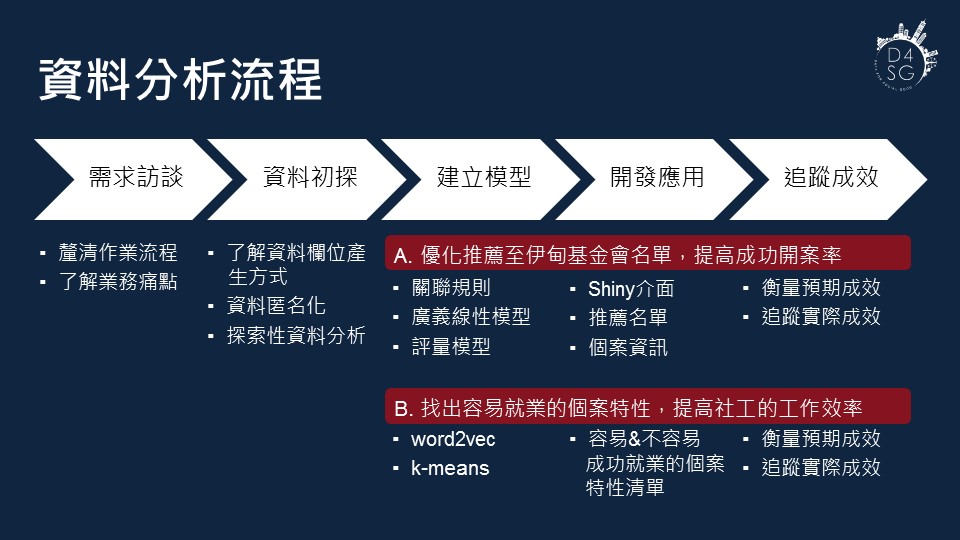
本次資料英雄將處理以下兩個議題:
A. 優化推薦至伊甸基金會名單,提高成功開案率
B. 找出容易成功就業的個案特性,提高社工的工作效率
資料英雄根據資料分析流程先進行需求訪談和資料初探,實際了解工作流程細項與資源,再針對兩個議題規劃不同的資料分析策略。
議題A:優化社會局推薦至伊甸基金會名單,提高成功開案率
一、用關聯規則萃取重要變數
先利用關聯規則萃取出重要變數,社會局的資料變項有三種類型,人口變項包含性別、年齡、教育程度等變項;家庭因素包含家中0-6歲小孩人口數、7-12歲小孩人口數、65歲以上長者人口數等變項;收入相關則包含收入等級、補助金額等變項。
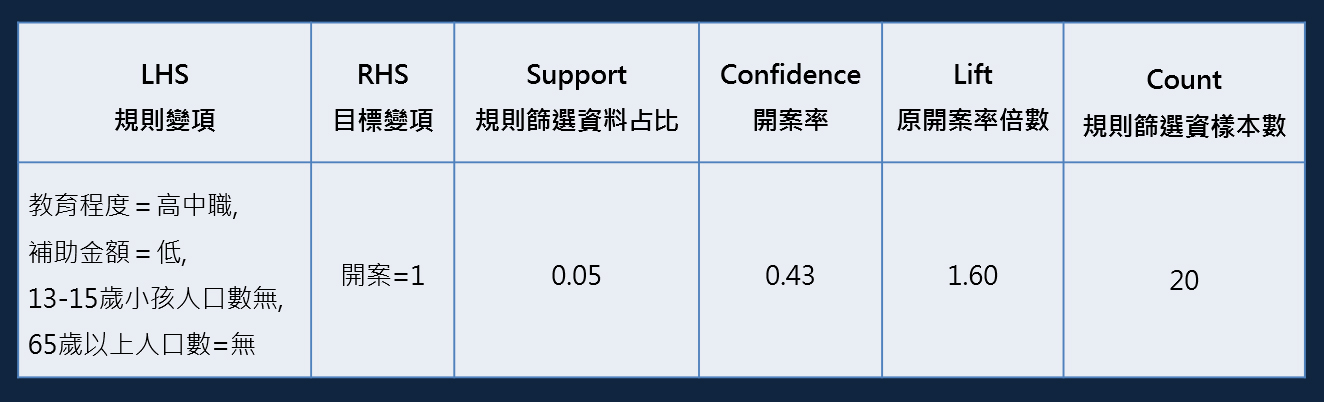
實作關聯規則是採用R語言的arules套件,參數設定包含最小規則長度為3(minlen=3)、規則所篩選出的最小樣本佔比為1%(support=0.01)以及樣本的最小開案率為8%(condifence=0.08)。將結果以Lift排序,以排序第一的規則為例,輸出如下表。
對於「教育程度為高中職、家中補助金額低於36K、沒有13-15歲小孩、沒有65歲以上長者」這個族群而言,佔訓練資料中的1.9%,開案率為25%,是訓練資料8%開案率的2.79倍。
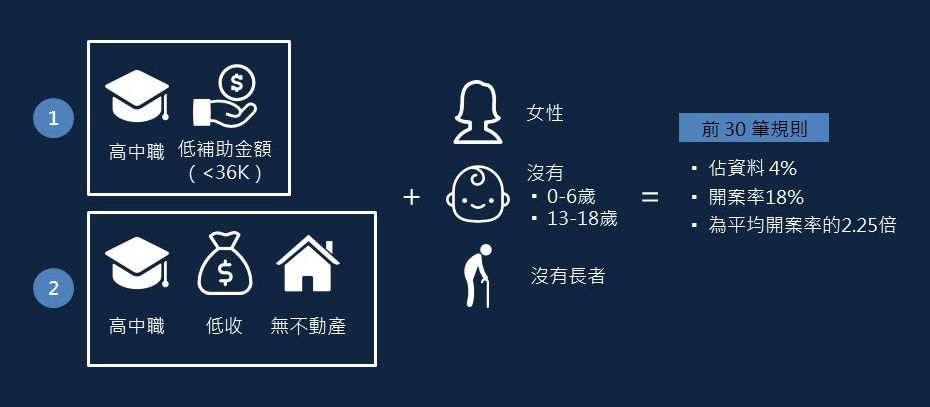
根據排序前30筆規則,歸納出以下兩種族群具有比較高的開案率:
1. 教育程度為高中職且補助金額低於36K
2. 教育程度為高中職、收入為低收等級且沒有不動產的紀錄
除此之外,其他與開案成功相關的重要變項包含女性、無0-6歲小孩、無13-18歲小孩以及無65歲以上長者。
二、用廣義線性模型優化社會局推薦名單
1. 動機與目的
關聯規則讓我們有一個依循的準則,可以判斷哪些人開案成功的機率較高,而這樣的準則是藉由confidence、support、lift等類似條件機率的指標篩選而出。但是對於每一個個案,我們仍想要給予一個預測開案的分數,於是我們決定建立模型,並以此模型的分數做出排序,優化推薦名單。
2. 方法
在選擇預測模型時,我們考慮了兩件事:
(1) 必須將關聯規則所挑選出的準則,其準則中的變數,納入考量
(2) 模型要能自動依據變數的顯著程度或重要性做調整
在不同的狀況下,有不同的適用模型。而在預測個案是否會開案的狀況中,我們的訓練資料,其反應變數為二元,解釋變數有類別型與數值型,最終希望模型可以再輸入個案特徵後,給出成功開案的機率。因此,廣義線性模型或是樹類模型(例如隨機森林與 XGBoost)都是符合我們期待的,但是結合我們的上述兩點考量,我們決定使用廣義線性模型作為我們的預測模型,因為我們比較熟悉廣義線性模型的操作,此外,對於模型調整的自由程度也比較高。
以下是我們我們建立模型的流程:
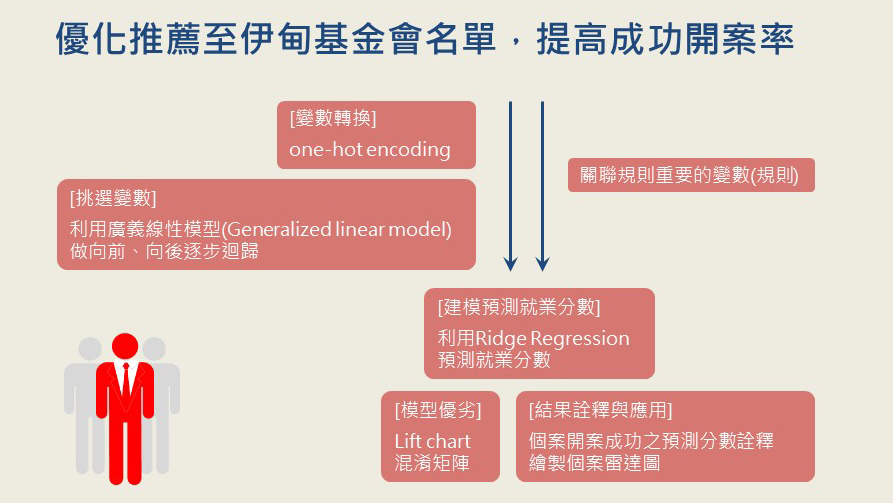
(1) 將類別型變數做 One-Hot Encoding 轉換
為了可以將類別型的解釋變數放入模型之中,我們參考脫貧政策上的業務流程,將類別型變數做清理,並使用one-hot encoding 做轉換。
(2) 利用逐步迴歸的方式,依照解釋變數的顯著性,做挑選
向前、向後的逐步迴歸的變數篩選,使用的標準是模型的 AIC 指標。將向前、向後的逐步迴歸篩選出的變數做聯集。
(3) 使用 Ridge Regression 的方法,以避免共線性及過度配飾的問題
將上述挑選出的變數,與關聯規則的準則中的重要變數做結合。因為納入的變數可能有共線性的問題,因此我們使用 ridge 的方法避免該問題的發生。
(4) 利用 Lift Chart 與混淆矩陣的方式,做模型與成效評估
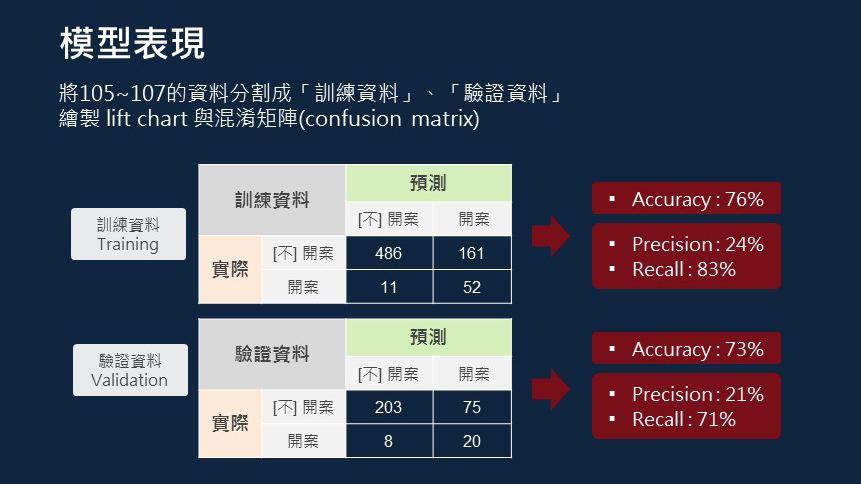
除了利用混淆矩陣,觀察整體模型的 Accuarcy、Precision、Recall 之外,也將名單分組,繪製 lift chart 觀察每組的模型成效。
(5) 將個案成功開案的分數 (機率),拆解成不同面向的指標分數
為了理解該個案成功開案機率的組成因素,因此我們將模型的解釋變數做分組,將每組的數值加總並作標準化,計算出該個案的開案機率在不同面向表現的指標。
3. 結果詮釋與評估
以下是我們利用 105~107 年度的資料,以 80/20 的分是拆成訓練與驗證資料集,並依照業務需求,我們希望在一定的 precision 下,盡可能地提高 recall 的數值,也就是說,在可接受的精確度下,盡可能地抓出每一個會成功開案的個案。
而透過訓練集與驗證集的模型表現,可以確信模型沒有過度配飾的情形。
最後,我們將變數分為五大組,分別是「收入財產」、「依賴輔道列計人口」、「教育」、「住宅環境」、「基本資料與意願」,將所有個案的分組數值加總後,對每組使用 min-max 標準化轉換相同尺度的分數,最後就可以繪製出,每一個個案在五大指標的成功開案表現。
4. 未來展望
雖然廣義線性模型的表現不差、解釋能力與模型成效也滿足我們的需求,但是如果要追求更好的模型表現,或許樹類模型是一個可以考慮的方向,但是樹類模型中,變數的篩選是依據分類結果後的重要性做為指標,在意義詮釋上可能要多加留意。
議題B:找出容易成功就業的個案特性,提高社工的工作效率
一、找出伊甸基金會輔導個案中,容易成功就業的特性
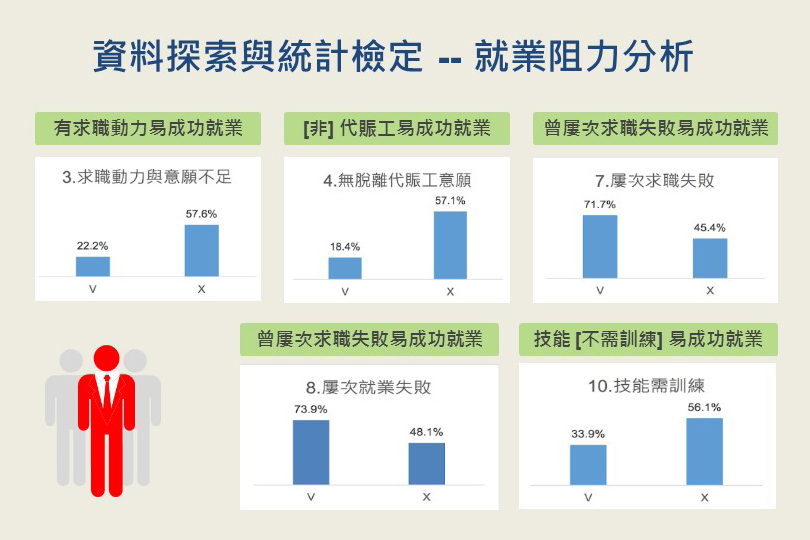
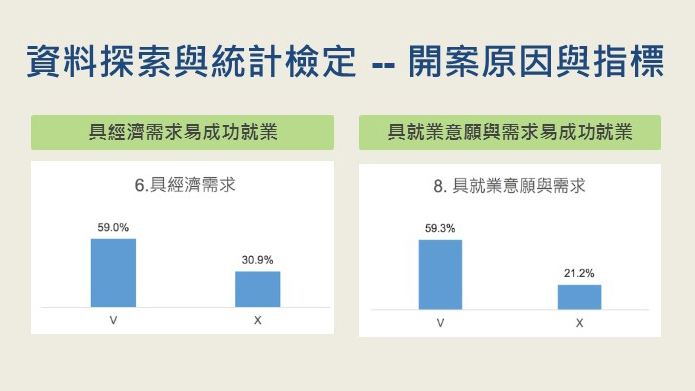
資料來源為伊甸基金會的個案服務月報表,主要參考與個案本身行為與特質有關聯的就業阻力分析、開案原因與指標。以 t檢定衡量不同就業阻力、開案原因,具備哪樣特性的個案比不具備此特性的個案在穩定就業成功率上有顯著差異。
統整結果,具顯著差異的個案特性列表如下:
- 有求職動力易成功就業
- 「非」代賑工易成功就業
- 曾屢次求職失敗易成功就業
- 曾屢次就業失敗易成功就業
- 技能「不需」訓練易成功就業
- 具經濟需求易成功就業
- 具就業意願與需求易成功就業
二、嘗試以伊甸基金會資料,建立成功就業預測模型
1. 資料來源:伊甸基金會提供103~107 年度資料
(1) 個案服務月報表 (Excel檔),選擇欄位有:
.個人身分資料 : 自接案、性別、年次、身分別、家庭角色、教育程度、接案時就業狀況、目前就業狀況
.就業阻力分析(可複選) : 自信心缺乏、職訓需求…等等
.開案原因與指標(可複選) : 就業心理障礙、就業準備不足…等等
(2) 個案評估表 (word檔) ,選擇欄位有:
.就業助阻力評估 (文字檔)
2. 建立預測模型,分為有無加入文字資料做訓練
(1) Case 1 : 僅使用個案服務月報表的資料進行建模
僅使用個案服務月報表中的三個欄位別,個人身分資料、就業阻力分析和開案原因與指標,運用 SVM 進行建模,針對資料不平衡的問題,運用調節各種類別樣本數量的權重,樣本數越多,懲罰項越小,反之懲罰項越大。
在 Case 1 下,提出個案是否能成功就業的預測模型,performance 表現為 AUC(Area Under Curve) : 0.724。
(2) Case2 : 使用個案服務月報表和個案評估表中的文字處理
對於個案評估表中的文字處理,要能斷出好的詞,就需要有一個完整的字典,這邊運用 Jieba 進行斷詞和 TF-IDF 進行字典校正。

詞頻 TF(term frequency) 是指某一個特定的「詞」在該文件出現的頻率,逆向文件頻率 IDF (Inverse Document Frequent),IDF 會將較常見的詞較小的權重,IDF 值的大小與詞的常見程度成反比,TF-IDF 的權重為 TF*IDF ,這邊可以透過 TF-IDF 權重較大來找出文章的獨特詞,下圖為某篇文章的文字雲。
之後將每篇文章的斷詞轉換成向量的形式,計算出向量空間的相似程度,之後我們利用分群的方式將相似詞分自同一群,之後將這些群當作我們新的 Feature 放入我們的 model 之中,再加入新的 Feature 後,performance 表現為 AUC(Area Under Curve) : 0.735 。
3. 結論
在模型中加入文字 Feature 比起未加入文字 Feature 的效果 AUC 僅提升 0.011,在實作時遇到了 word 檔樣本數太少,導致不能增加太多停用詞,若增加資料量,可建立較完整的文字庫,或許有機會提升 performance 的表現。
專案預期成效
1. 優化推薦至伊甸基金會名單,提高成功開案率,預期可以提高開案率4~5倍
- 社會救助科利用Shiny介面,每年從約6,684筆符合資格的名單中篩選300~400名單委案給伊甸基金會社工經營
- 選取到的名單為模型分數最高的前300~600名,開案率預估值為37%~45%,是原人工篩選規則的4~5倍
- 模型限制:模型訓練時採用的名單皆有委案給伊甸,但全部資料庫內的名單大多未曾提供給伊甸
2. 找出容易成功就業的個案特性,提高社工的工作效率
- 伊甸基金會可參考判斷成功就業個案的特性清單
- 調整優先處理個案之排序,以作最有效的人力配置
- 針對這些特性建立快速找到實際原因的訪談方式
- 職前準備的課程多針對該特性對症下藥
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021
