
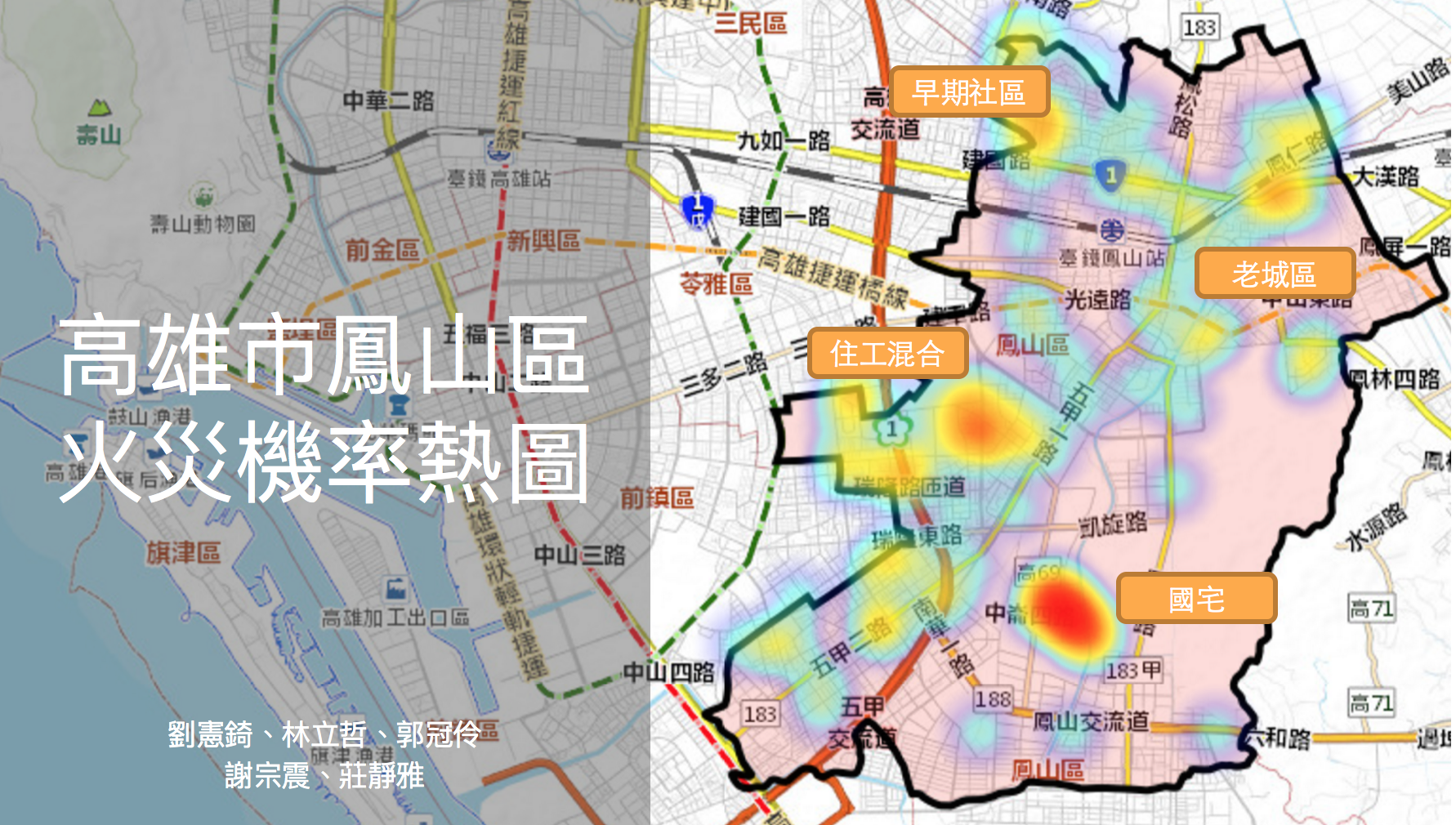
建築物火災風險地圖
Fellows:劉憲錡、林立哲、郭冠伶
Mentor:謝宗震
Project Manager:莊靜雅
Project Partner:高雄市政府消防局
Introduction
高雄市消防局自成立以來,咸奉「預防火災」、「搶救災害」、「緊急救護」之消防三大任務及其他為民服務事項,共同努力。為達成積極主動為民服務之使命,消防員24小時受理民眾需求並隨時出勤執行各項救災救護任務。每次的出勤任務都代表著人民傷亡或財物損失,同時也耗費國家的人力資源,卻無法徹底解決問題,因此預防火災便成了消防局積極推動的首要目標。
Problems
有鑑於住宅火災佔總案件數一半以上,高雄市消防局加強宣導住宅社區火災預防措施。但如何善用有限人力與資源,進而顯著降低火災發生頻率,一直讓消防局苦無對策。於是消防局與資料英雄合作,冀望能從建築物角度出發,彙整住戶與周遭環境資料以建構出建物火災風險預測模型,進而找出高風險住宅戶做居家訪視與社區消防觀念宣導,此外,本專案交叉分析不同數據,希望從中闡述新穎觀點以作為決策參考。
Method
資料處理
為評估建物火災機率,建築物火災風險地圖是以建物門牌號作為每一筆資料的索引,在高雄市政府機關大力的配合下,取得自稅捐處取得十三萬餘筆左營區地價資料、地政局建照十三萬餘筆建照資料。透過 Python 與 SQLite 反覆比對地址以及對地址進行正規化處理後,我們合併出約八萬九千筆資料。另外,根據金門大學火災預測碩士論文(link),承蒙社會局提供左營區身障、低收、獨居老人資料,加上消防局的狹小巷弄、火災報案紀錄,我們整理出以下特徵值。
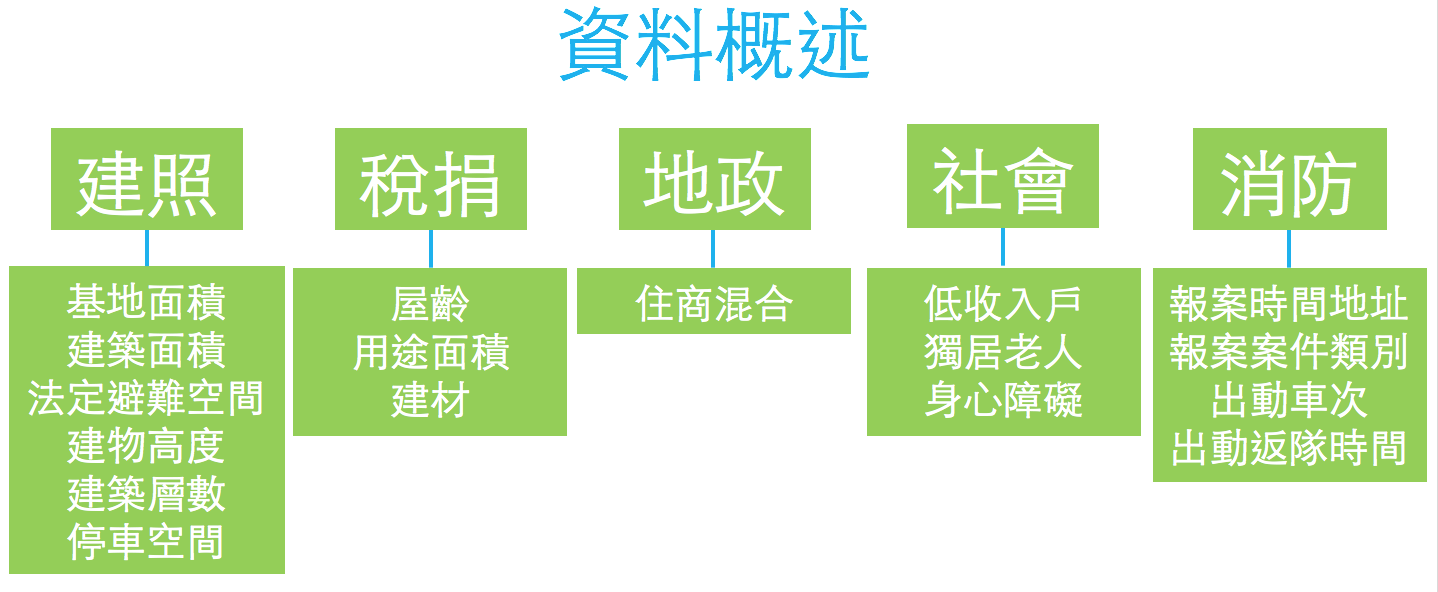
資料處理實際上是這次專案花掉最多時間的地方,因各處室資料格式繁紊不一,資料整併窒礙難成。冀望將來,市府能將跨處室之集中資料倉儲作為資訊基礎建設之基石。
平衡學習 & 非平衡學習
在訓練建物火災機率模型初期,我們嘗試以深度學習演算法建置模型。我們得到 99.9% 的準確度,而後發現模型預測所有的建物都不會失火,因訓練資料中未失火的建物佔絕大多數,僅約四百筆建物曾失火,模型無法學習到失火建物的特徵,故模型猜測沒失火,且可藉此得到高準確度。
建物火災機率預測實為典型的非平衡學習,而準確度之於非平衡學習不是個好的指標。我們發現我們的初期模型在召回率方面的表現非常差。參考過往文獻後,我們決定以 BalanceCascade 的方法來訓練模型。下面我們將一步步介紹如何實作 Blanace Cascade 方法。
首先,我們需要對所有未失火的建物進行分群。我們將建物分成 137 群,每一群擁有八百筆建物資料。為此,我們採用了kNN(k-Nearest Neighbors)演算法。
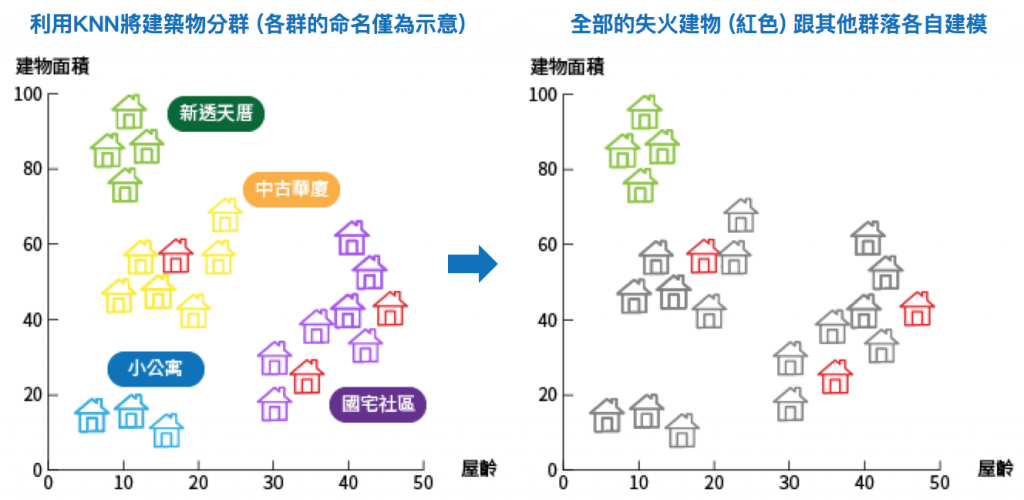
左上圖是分群後的示意圖,並非真實的分群情況。我們可以想像分群後,總樓層數相近的建物會被分成一群,如左下角藍色建物群,大致可以定義它們為小公寓群;而右方屋齡較高的紫色建物群則是早期的國宅設區,以此類推。
分群過後,我們把一群八百筆未失火的建物和全部四百筆失火建物放在一起訓練小模型 (如右上圖所示)。這邊我們使用基於隨機森林(Random Forest)的 XGBoost 演算法。不採用深度學習演算法是因為小模型太多、分佈沒有一致性,致使訓練過程不易收斂。
Results
火災機率模型
如同前言所述,我們將建物火災風險拆成建物火災機率和預估損失兩個模型。在建物火災機率模型中,我們透過非平衡學習得到火災機率模型。在整體模型驗證評估後,我們的模型準確度達 88%,而在召回率亦有 78% 之良好表現。
資料分析結果
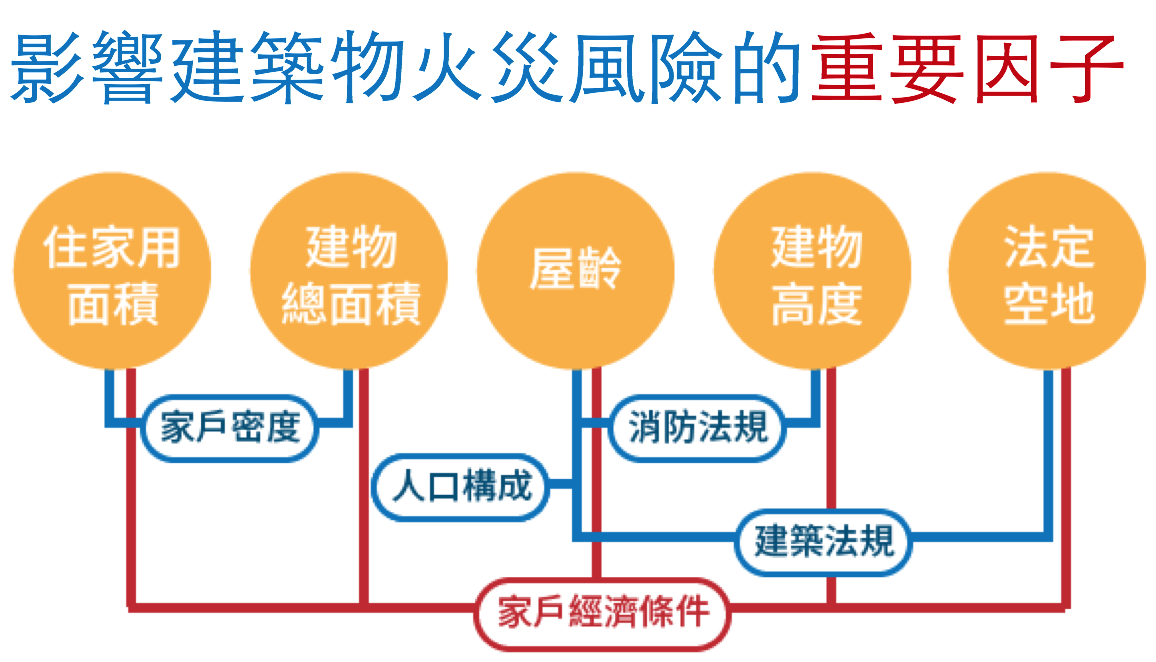
我們從模型反推 XGBoost 之決策樹結點,對重要因素進行分析。我們發現前五大重要特徵屬性分別為住家用面積、建物總面積、屋齡、建物高度、法定空地。
更一步分析發現,若將兩兩特徵屬性交疊,考量他們的相互變動,可間接得到我們最一開始無法取得的資料。例如住家用面積高但建物總面積相對低,則可得出家戶密度偏高,這是我們認為和火災機率高度相關,但無法直接取得的原始資料。另外像是屋齡和建物高度,則可反映出民國 85年內政部消防署修正頒布之《各類場所消防安全設備設置標準》,提高了法定高度的建築物內部消防安全設備所需達到的安全標準 。此外,屋齡、建物高度和法定空地則可間接看出容積率之變革,以及其對於火災發生機率之影響。
除家戶密度、屋齡、容積率等因素外,進一步思考可發現這些因素背後的根本原因皆為家戶經濟條件。如老舊社區之家戶經濟條件得以負擔新成屋房價,他們就不需要承擔這些高火災因子。
從總體經濟學的角度來說,我們一般只認為高房價、貧富差距只是讓經濟條件中低層的人過苦一點的生活。但從這次的火災機率因素看來,無形之中愈趨兩極化的居住環境加劇了火災之於中低階層的財產及生命威脅,更加諸社會的外部成本。
實務效益
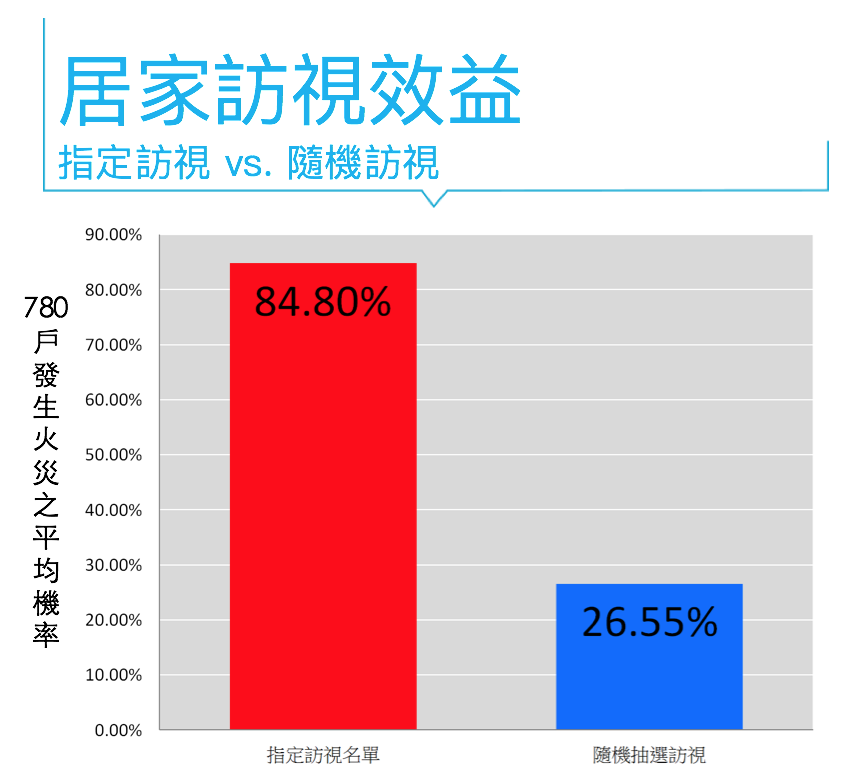
高雄市消防局火災預防科提到,每個月各大消防分隊都會對所在轄區進行消防安全居家訪視,就住家用火、用電、瓦斯、防汛、避難逃生等可能潛在危險因子,與住戶面對面訪談,提供防災建言,並指導製作家庭逃生計畫及演練。以鳳山區為例,規定每月訪視戶數為 780 戶,然而整個鳳山超過 13 萬戶,透過我們的資料分析模型可以計算出鳳山所有建築物的火災發生機率,並依照機率大小進行排序。就訪視 780 戶的平均火災發生機率而言,依照機率較大的建築物優先訪視與隨機訪視的比較結果是 85% 比 27% (如下圖所示)。
Discussion
本次專案因為時間與人力的限制,因此僅挑選單一行政區做為實驗區域。考量到建物型態之多元性以及代表性,挑選鳳山區為本次專案之實驗目標。理論上可以將其餘行政區或是縣市之資料套用本次專案建置之模型,取得相關之建物風險,但仍需經過進一步的精度驗證,來確保資料之使用。
本次專案主要的困難點有兩項,一項是非平衡學習,另一項為原始資料之清理。資料清理主要之難處也有兩項,一項是跨部門之資料不易進行關聯,另一項為描述性資料轉化為量化資料。於本次專案中所謂的不易進行關聯,意指各項資料的提供之地址格式不一,有全形半形之問題,也有中文數字與阿拉伯數字之問題。同時也有A資料內的地址無法再B資料內找到這種資料損失的情況。而描述性資料轉化為量化資料則是指消防相關資料有很多都是已描述性之方式紀錄,例如案發地點、案件類型、處理情形等。探究兩項難處之根本原因其實都是因為既有資料之紀錄及收集方式並未考量機器讀取以及後續分析之需求,大部分之資料都是各項業務之副產品,很少以資料為中心來思考。希望政府未來能考量資料導向之作法,同時提升資訊基礎建設。
本次專案建立了高雄市鳳山區各個建物的火災風險模型。以此模型為基礎,可以提升火災預防宣導之效率。未來除了可以將風險模型之地理範圍擴大(更多縣市、更多行政區),也可以與消防局的業務進行更深入的結合,了解消防業務之決策需要那些洞見。
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021

1 Comment