
採購稽核智慧化

Mentor:劉嘉凱
Project Partner:臺北市政府工務局採購科
問題描述
每個月稽核委員完成現場查察後須依限撰寫稽核報告,將查證結果以三段式寫法呈現,分別為「法規依據」、「違規事證」及「改善建議」,並送交稽核小組查核員同仁進行校稿彙整。當採購稽核委員在系統輸入缺失意見及其援引法規時,容易誤用法規,因此台北市查核員經常需要花費大量心力協助調整為正確法規。
希望藉由「法規推薦」的方式,在委員輸入缺失意見時,自動推薦相關的法規,降低錯誤使用法規的頻率,提升委員稽核報告之撰寫效能與品質。
分析方法
一、流程概述
依據市府提供資料進行討論,補足相關資料後進行推薦系統的設計,並重複進行準確率評估和調整模型。
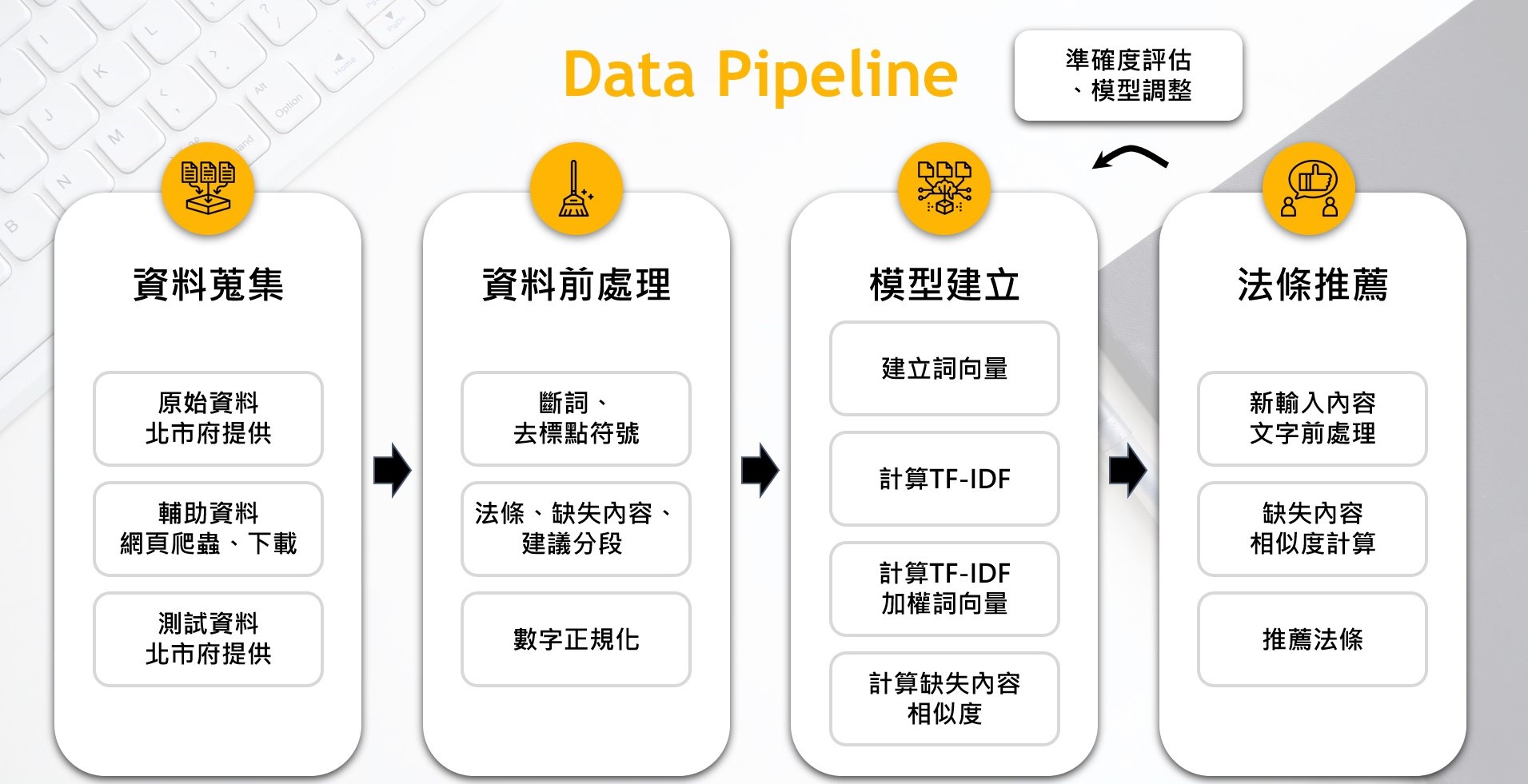
(一)、資料蒐集
除了北市府提供的訓練資料和測試資料外,我們依據建模需求,藉由網路爬蟲蒐集相關輔助資料。
資料清單
- 訓練資料:200801至202008缺失類型(法規分段例),法規的部分有23,228筆。
- 測試資料:原始意見及定稿意見彙整表_v3,共49筆。原始意見為委員原本輸入的文字,定稿意見則為稽核同仁修改後的版本,用詞較為一致。
- 輔助資料 – 移除法規:法令依據/事實/改進建議分段,法規跟錯誤態樣各50筆。
- 輔助資料 – 移除法規:法令依據/事實/改進建議分段,法規跟錯誤態樣各50筆。
- 輔助資料 – 字典:法規字典、法規切分字典。
(二)、資料前處理
對原始資料和另外蒐集的輔助資料進行資料前處理。
以下為處理步驟:

(三)、模型建立及模型評估
進行資料前處理後,我們開始進行模型配適以及評估。
反覆使用不同模型進行訓練,再比對測試結果準確度,找到最高準確度的模型。
二、探索式資料分析(EDA)
在訓練資料的筆數分佈上,政府採購法的占比最高,將近三成,樣本的分佈不均可能會有兩個影響,一方面是樣本足夠的類別會得到較多的資訊,推薦成果較為準確,部分過少樣本可能因為資料不足而無法取得充足的資訊,而成效較差。
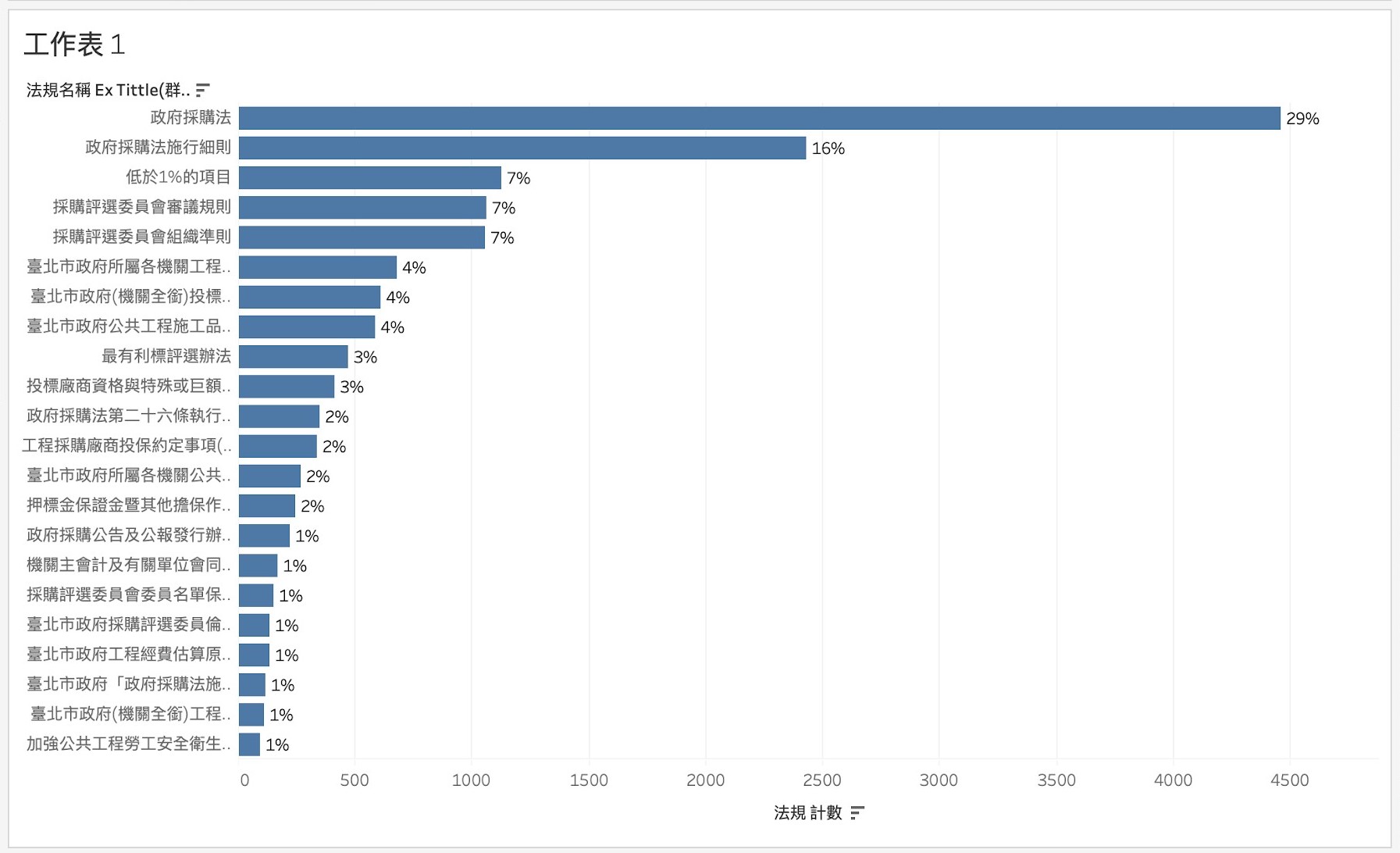
訓練資料的法規名稱的筆數分佈
測試資料集上,與訓練資料筆數分佈較為不同的有 「採購施行細則」與「採購評審委員會組織準則」,分布都較高,分佈的不一致也會影響最終成效。
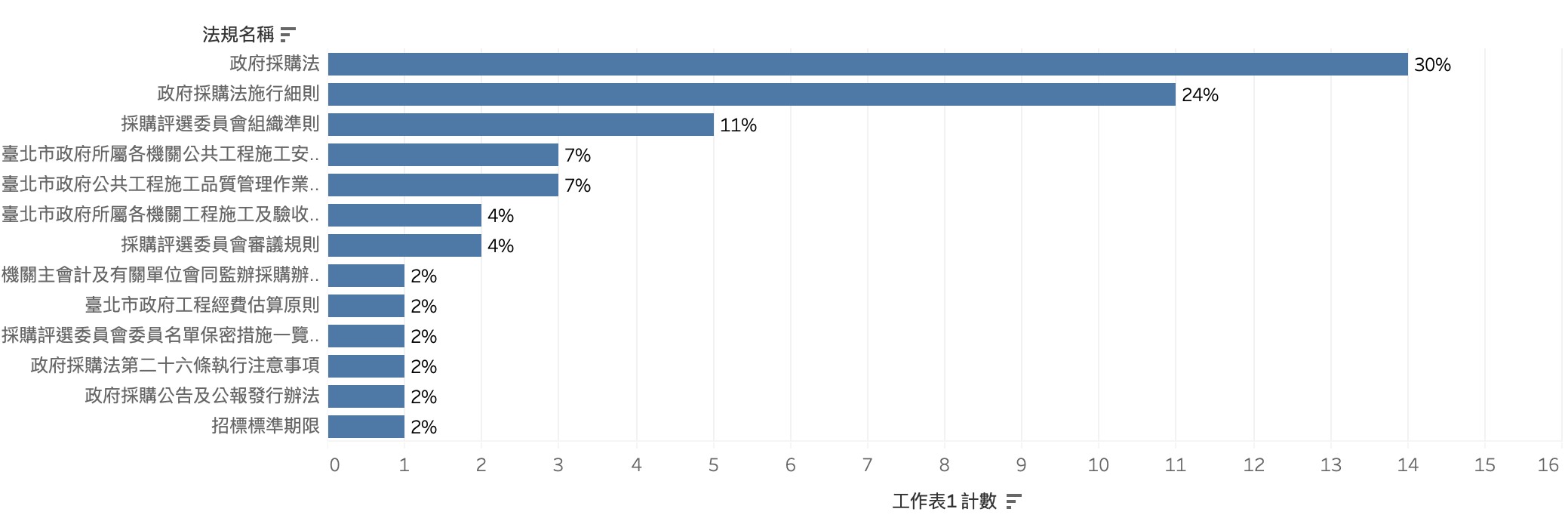
測試資料的法規名稱的筆數分佈
總結:
- 政府採購法占比近三成,整體分類項目達七百多項,部分法規樣本數不足。
- 部分較早資料會有複數法條,需要排除。
- 訓練資料是公部門調整後的用語,與日常用語較為不同,當輸入資料為日常用語時,可能推薦的結果會與預期有所不同。
三、解決方案
(一)、效益
在日常稽核作業中,稽核委員完成現場查察後須依限撰寫稽核報告,將查證結果以三段式寫法呈現,分別為法規依據、違規事證及改善建議,並送交稽核小組查核員同仁進行校稿彙整,整個過程相當繁瑣且需要花費大量的心力與人力檢視報告的正確性,將意見潤飾調整後,匯入系統資料庫,所以希望能夠過人工智慧方式協助日常的檢視,減輕相關作業人員的負擔。藉此我們採用新穎技術建立推薦模型,在委員每次撰寫報告過程中,可以根據撰寫內容推薦且自動帶出適合的法規,有效提升尾約稽核報告之效率與品質,另外也能減少查核同仁二次作業,達到線上e化的作業流程。
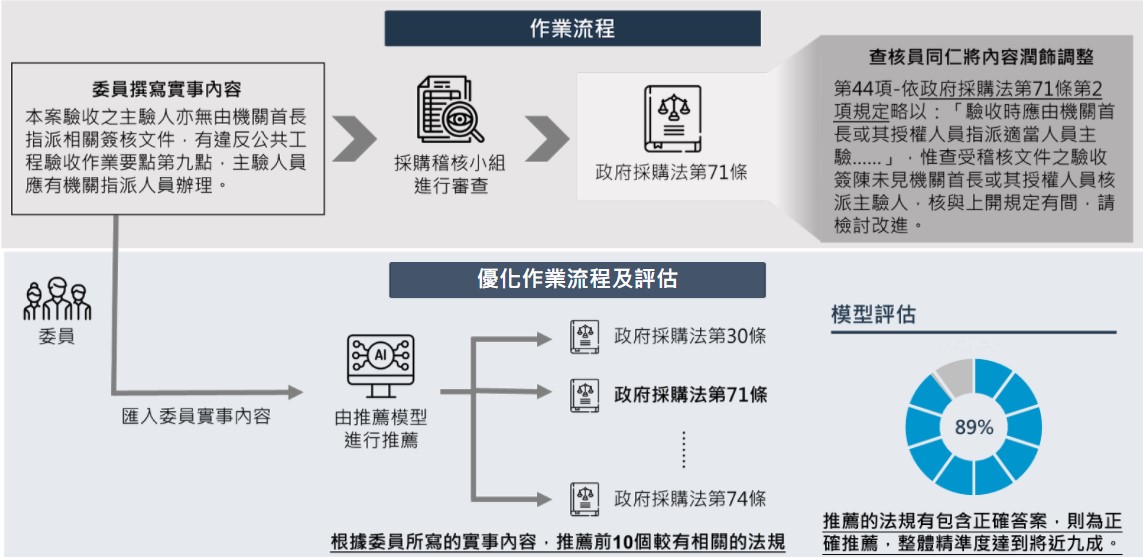
(二)、方法
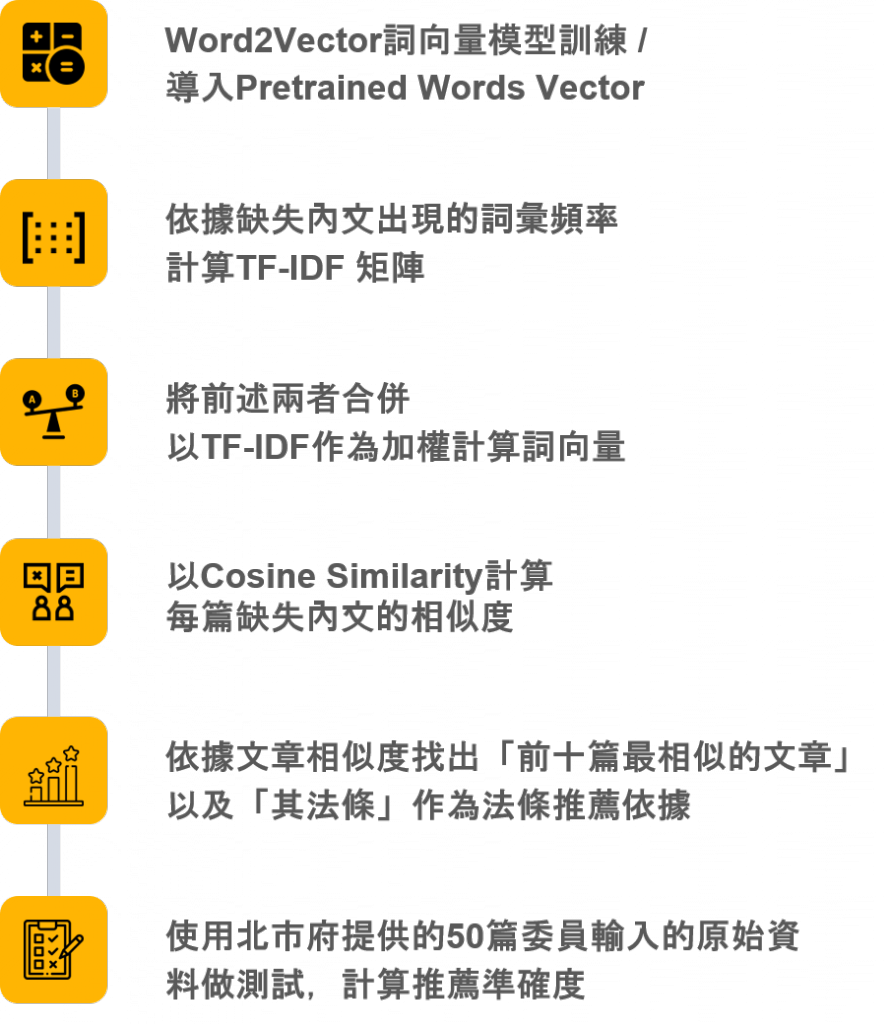
目前採取兩種方法技術從撰寫報告內容中萃取豐富的資訊,結合這兩方法並以內文相似性進行推薦,達到精準推薦合適法規。
- 第一方法 : 語意學習
以 Word2Vecotor 方式訓練 WIKI 語料庫,並將詞彙轉化成向量來表示字詞語意,且可以明確指出相似與相反字詞,達到理解字詞間的關聯性,接著套用於稽核報告中,將其轉換向量。
- 第二方法 : 量化字詞的重要性
可藉由 TF-IDF 方式來衡量字詞的重要性,也就是將重要且富含意義的字詞進行標註,凸顯重要採購關鍵字詞,進而協助模型進行相似性比對,提升模型推薦的精準度。
- 相似度推薦
最後採用相乘方式將詞向量與字詞重要性進行整合,並將文本的計算後的向量進行加總,彙總成事件的向量,因次可藉由這個向量進行相似性比對,精準推薦與委員撰寫稽核內容的適合法規。

優化作業流程及評估
(三)、分析結果
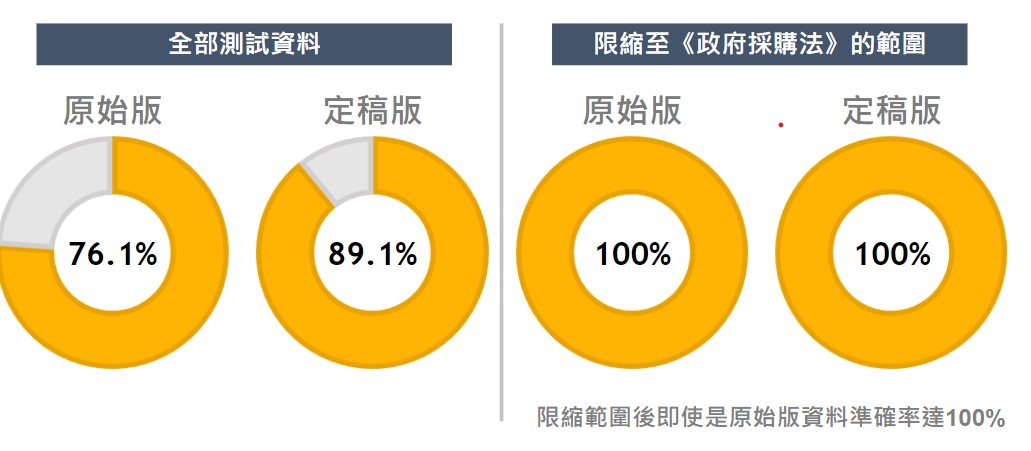
- 以工務局提供的近50筆測試資料,原始內容可以達到76.1%。調整後的定稿版可達到89.1%。
- 再將測試資僅篩選政府採購法範圍,原始內容可以達到100%。調整後的定稿版可達到100%。
建議與未來展望
- 資料來源方面:
- 提升資料品質,例如可先依法條、事實、建議分別輸入資料庫,而非未分段之下直接輸入資料庫,以提升訓練資料的品質。
- 若想將法條推薦系統延伸至其他面向,像是錯誤態樣,或市府新增的15條分類,建議固定每一條分類內容與對應的編號,此項對應不可隨時間推移而變動。
- 使用時可當作搜尋引擎,輸入有代表性的法條關鍵詞。
- 演算法方面:
- 增加特定語料來源(公文書寫、採購專業等),和維基百科一起進行詞向量模型訓練,彌補泛用型詞彙的不足。
- 採用更加精準的斷詞方式切出領域特殊詞彙。
- 加入前後文關係至目前的詞向量加權模型。
- 用不同演算法例 BERT + word pieces。
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -
智慧防洪,韌性城市
22 8 月, 2019
