
預測模型的準確率 99.9% 就夠了嗎?錯,鍵盤打火英雄告訴你該怎麼辦!

如何有效運用人力與資源來宣導火災預防觀念,進而降低火災發生率,一直是高雄市消防局終極目標。
有別於火災風險地圖 1.0,消防局冀望能從建築物角度出發,彙整住戶與周遭環境資料以建構出建物火災風險預測模型。經過多次討論,決議以各式建物混雜的鳳山區為例,希望用機器學習方式得到預測模型。資料英雄用8萬筆資料訓練 DNN 模型,哇!準確率幾乎百分之百,這一切都太完美了,對嗎?
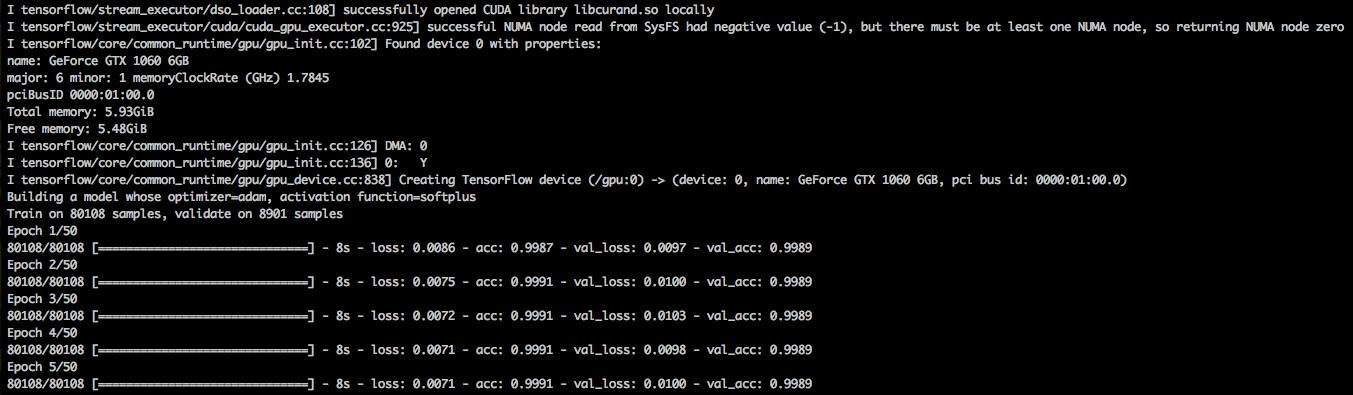
錯!建物有上萬棟,但實際在104到105年間發生過火災數量卻不到一百,像這種非均衡的二分類數據 (1:800) 實務上很常見,高準確率的模型往往只預測一種類別,這就是 Accuracy Paradox!
遇到數據失衡時,我們能怎麼辦?
1. 擴大時間範圍,蒐集更多歷年火災資料
新增多筆歷年火災資料,並重複抽樣出比例均衡的小樣本來訓練模型,來避免數據失衡的問題。
2. 用不同抽樣方法來抽取樣本
下面條列一些經驗法則:
a. 在母數少的類別中隨機複製資料
b. 在母數多的類別中隨機刪除資料
c. 考慮隨機和非隨機的抽樣方法,如分層
d. 考慮不同比例的抽樣方式
3. 嘗試不同類型的演算法
試試其他演算法,如決策樹算法、CART 以及隨機森林等等,或許其他演算法能有效分類。
4. 調整權重因子
確定只能使用的演算法是適當的且無法採樣時,可藉由調整權重或是增加懲罰因子,來平衡數據類別。
5. 嘗試用不同角度或創新想法
考慮是否可以將其拆分為類似的小問題,如把大數據分成許多小類別數據。
許多方法都可嘗試,這次,資料英雄該如何快速找到最佳的方法來破解難題呢?敬請期待。
You may also like
-

[心得] 用數據預測危機,一個社工系學生的學習之旅
26 12 月, 2017 -

D4SG資料英雄計畫-提案單位常見問題集
1 5 月, 2017 -

[心得] 用數據來溫暖社會,一場家暴防治的奇幻旅程
29 3 月, 2017
