
如何評估學生學得會?

Fellows:黃卉怡、柯景泰、林芃彣、楊佩雯、游家鑫、張育慈
Mentor:劉嘉凱、梁智程
Project Manager:蔡子揚
Project Partner:誠致教育基金會
緣起
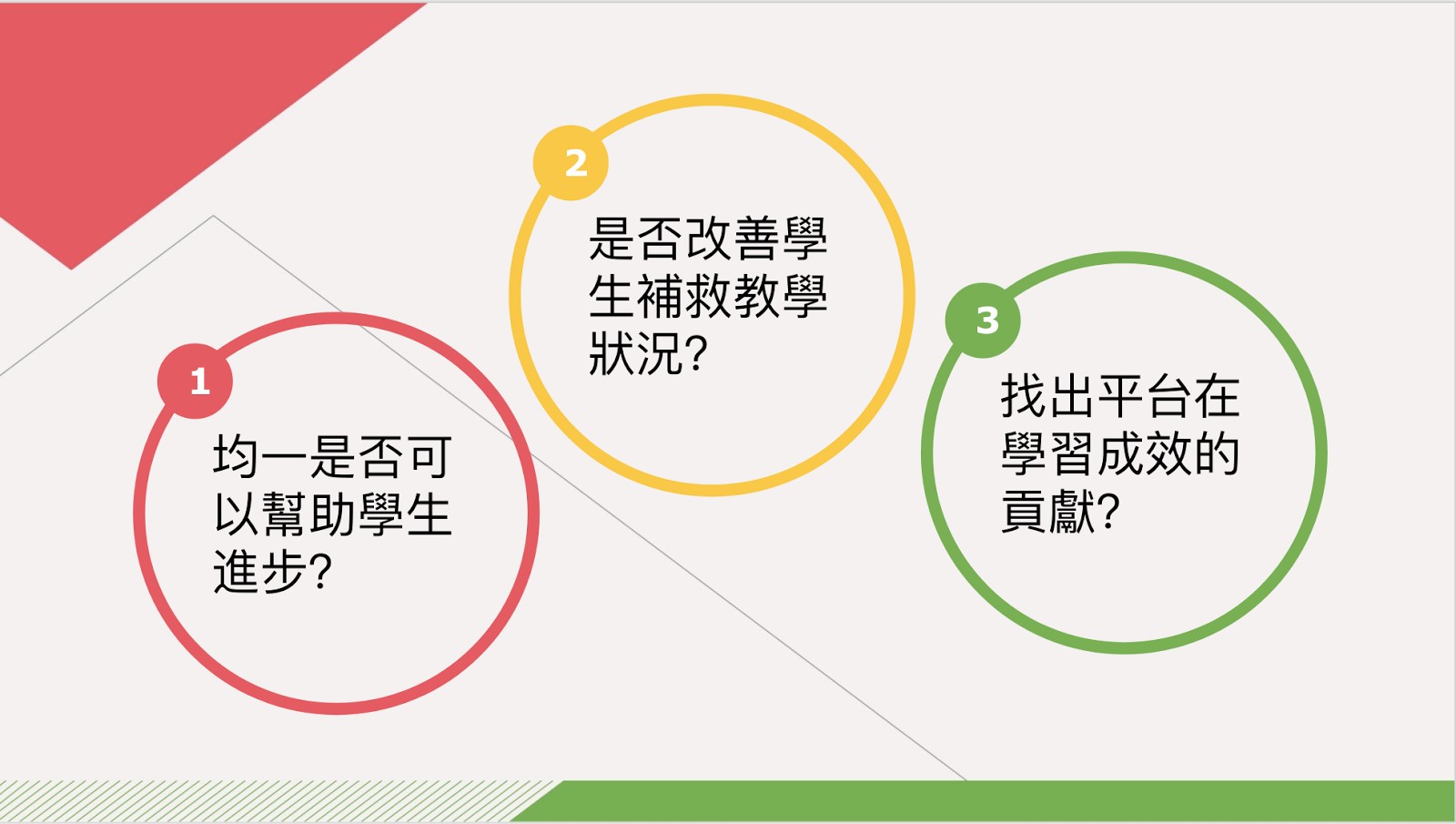
如何衡量學生學得會?
均一教育平台致力於提供所有學生「均等」且「一流」的學習機會,以此做為我們的使命。均一教育平台設計是以個人化學習為概念,我們深信要落實個人化學習,必須尊重每一個孩子不同的特質與現況,並搭配「精熟學習」與「成長心態」之教育理念,讓每個孩子重新體驗自己有學會的機會!
近年來,不論是線上或線下,均一夥伴們皆努力探索不同的可能性,希望能與學校家庭共同合作,幫助孩子們在基本學力上的進步,而我們也常常問自己,孩子們真的學會了嗎?因此在數據上的蒐集與分析不停精進,希望能透過客觀可靠的科學方式,為我們的產品作改善,2016年更與台大林明仁教授進行專案合作,分析宜蘭縣的小學生,經過兩年學習歷程看到,宜蘭縣的學生能使用平台3.5小時,且在均一教育平台上獲得超過13個練習題組精熟,學力檢測能提升14.2個PR值,這讓我們更有信心相信我們確實有幫助孩子們進步。
但是,我們不能因此驕傲自矜,在教育的路上我們仍有很長的一段路要走,證明了我們的產品確實可以幫助學生之後,更要知道是什麼地方確實幫助了學生?學生在學習上如何更有效率,讓進步的幅度能更上一層樓呢?線上線下,平台跟老師家長可以怎麼配合?這些都是我們希望能釐清的題目。
思考
聯合所有正面力量
我們常常聽到說:「不要重新發明輪子」。在誠致內,我們也常常告訴自己,要善用槓桿,聯合所有正面力量,站在巨人的肩膀上,讓自己更有效率地利用資源,於是在今年年中當我們看到 智庫驅動-D4SG資料英雄計畫,與公共服務性組織合作,選擇兼具高度社會影響力與再利用性的資料科學專案,並媒合民間熱血的資料英雄,利用三個月的工作時間共同完成,同時,有著熟稔資料科學的mentor們會帶領專案前進。我們認為這是一個很好的機會,利用均一內部大量的數據,結合外部人才在資料上的知識,希望能夠發揮1+1 > 2 的力量,了解往後平台在資料搜集與功能上可以做什麼改善,做到更緊密結合「網路」、「數據」與「教育領域知識」,進一步發揮教育科技創新。
同時,我們也希望能做到以下:
- 軟體公司的思維跟經營,重視速度與 O2O(Online to Offline)交叉運作
- 發揮團隊執行力,善用數據分析,避免斷點
- 公開透明 – 主動公開使用數據,取信於社會,並拋磚引玉,希望台灣其他MOOC也能公佈數據
過程
高手在民間
鄉民說得好:「高手在民間」。在D4SG計畫中,我們發現參與者背景非常多元,有上班族、主管經理、研究生等,不僅在本身領域上面有所成就,也願意奉獻自己的時間參與公益計畫,真正讓我們體會到 Data for Social Good 的精神。來說說合作的細節,流程如下:
- 認識產品
- 訂定題目
- 資料盤點
- EDA
- 特徵挖掘
- 建立總表
- 建立模型
- 結論與建議
認識產品
首先,雖然聚集了一群有志之士,但是在教育的領域上,大家都是初學者,對於產品與基金會的認識可能都不太熟悉,因此首要之務就是要幫大家「上課」,我們利用了均一教育平台上的教師資源區,讓大家了解老師及學生各自如何使用均一,例如:針對產品特色之一「精熟學習」,便利用「三分鐘了解精熟學習」影片進行解說,希望能讓各位高手快速跟平台接上線。這部分我認為在後續的作業上非常重要,尤其是產品的核心價值與使用情形,不用單單透過資料上的數字自行腦補,降低走錯方向的風險。

訂定題目
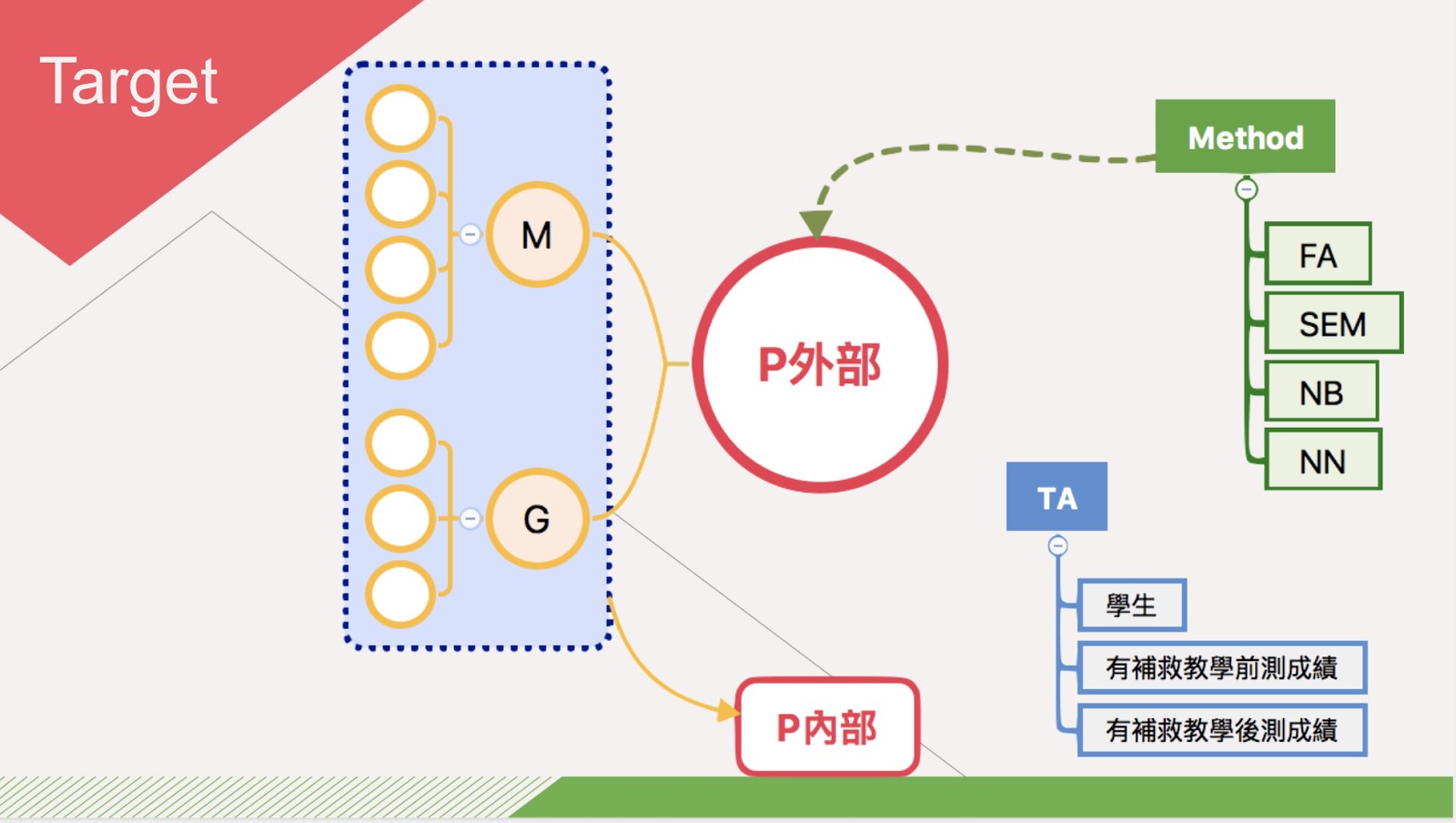
定義題目對於資料分析來說是極其重要的起手式,我們由老師的教學經驗,列出評估學生成就的可能題目如下:
- 老師對均一平台的使用行為與個人背景是否會影響學生之學習成效?
- 如何使用均一平台,提升補救教學的成效?
- 學生學習行為的成效預測
這些乍看之下看都是很好的題目,但我們必須用理性看待這個專案,在我們擁有的「人才特性」與「專案時間」以及「組織需求」來看,需要進行綜合評估。最後我們以「學生如何使用均一平台,以提升補救教學的成效?」作為初步的題目探討。
資料盤點
既然是資料英雄,想必資料就是最強武器,但是由於大家常用的工具都不盡相同,例如這次的組合,有BigQuery、SAS、Python、Rstudio、Jupyter ……,唯一的交集就是 csv 格式的資料了,因此需要在前期將相關資料轉成 csv 釋出,並提供解釋每一張 table 與欄位的定義。
有了資料後,結合產品資訊建立「資料旅程」,利用視覺化的行為,讓資料科學家們不只有資料,更了解資料的「流向」,清楚知道手上的數據代表的意義,可以更有效率地提出問題與需求,這部分需要基金會的同仁,包含工程師、推廣組員、教育組員的協助,合力協助科學家們建構這張可以隨時拿來「導航」的資料旅程。

EDA ( Exploratory Data Analysis )
就像有了目標(定義問題)、地圖(資料旅程)、燃料(資料)之後,現實中是不是真的有路可以帶領我們找到目標?於是「探路」就非常重要,EDA也就是探索性數據分析,對於手中的數據進行小規模探索,實驗,建表畫圖,看看重要的指標與特徵是不是有相關性。
例如:我們想利用補救教學成績來作為最後的驗證,那麼平台上的學生是否能對應到補救教學成績? 如果不行,那麼前期的規劃跟想像就是白搭,也就是說 EDA 可以降低我們在資料分析上的風險,像這一次就發現,補救教學資料在2016 的某一段有缺,因此在以預測補救教學成績為目標的前提上,並無法使用 2016 的平台行為做研究,必須退而求其次使用 2015 的資料。
建立總表
當我們發現影響學生的成效其實有很多「可疑份子」,那麼到底誰是主因呢?還是需要排列組合才能發發揮效果?
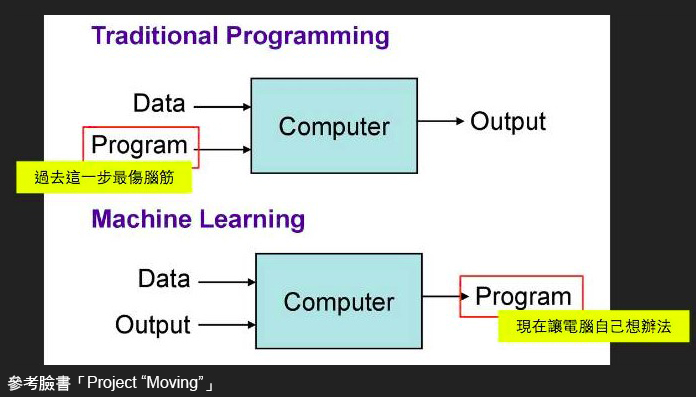
過去資料科學分析時,可能會有既定的 domain Knowledge 來領航分析,但是在現今這種多變數的情況下,domain Knowledge 已經無法快速有信心地告訴我們哪一個因子或是組合是可靠的情況下,我們指望利用機器的力量,概念就像下圖,我們已經有了 Data,也有了最後的期待值,那麼剩下的就交給電腦傷腦筋囉,因此掌握了這樣的原則後,我們再也不怕變數太多,無法有效的去排列解釋,進行分析,因此開始找出可疑的特徵,建立大表,而這張大表最後擁有了「263」個變數。
建立模型
在建模時,資料科學家們採用 XGboost、Kmeans、決策樹等方法嘗試,建立模型,找出幾項相關性較高的特徵,提供給均一內部研究。但要小心的是用ML作出的分析結果,可能是相關性高,但我們不能直接將其歸納為直接的因果關係。
以模型跑出來的結果,裡面有一條是「補救教學成績好的,影片使用時間越低」,這部分如果直接看可能會覺得跟平台認知有點矛盾,但有可能是成績本來就比較好的,不需要重複看太多次影片,因此影片使用時間較少,所以千萬不能被模型跑出來的結果給牽著走,畢竟現階段模型提供的是一個事實,至於各個事實之間的因果,還是需要靠人來做判斷。
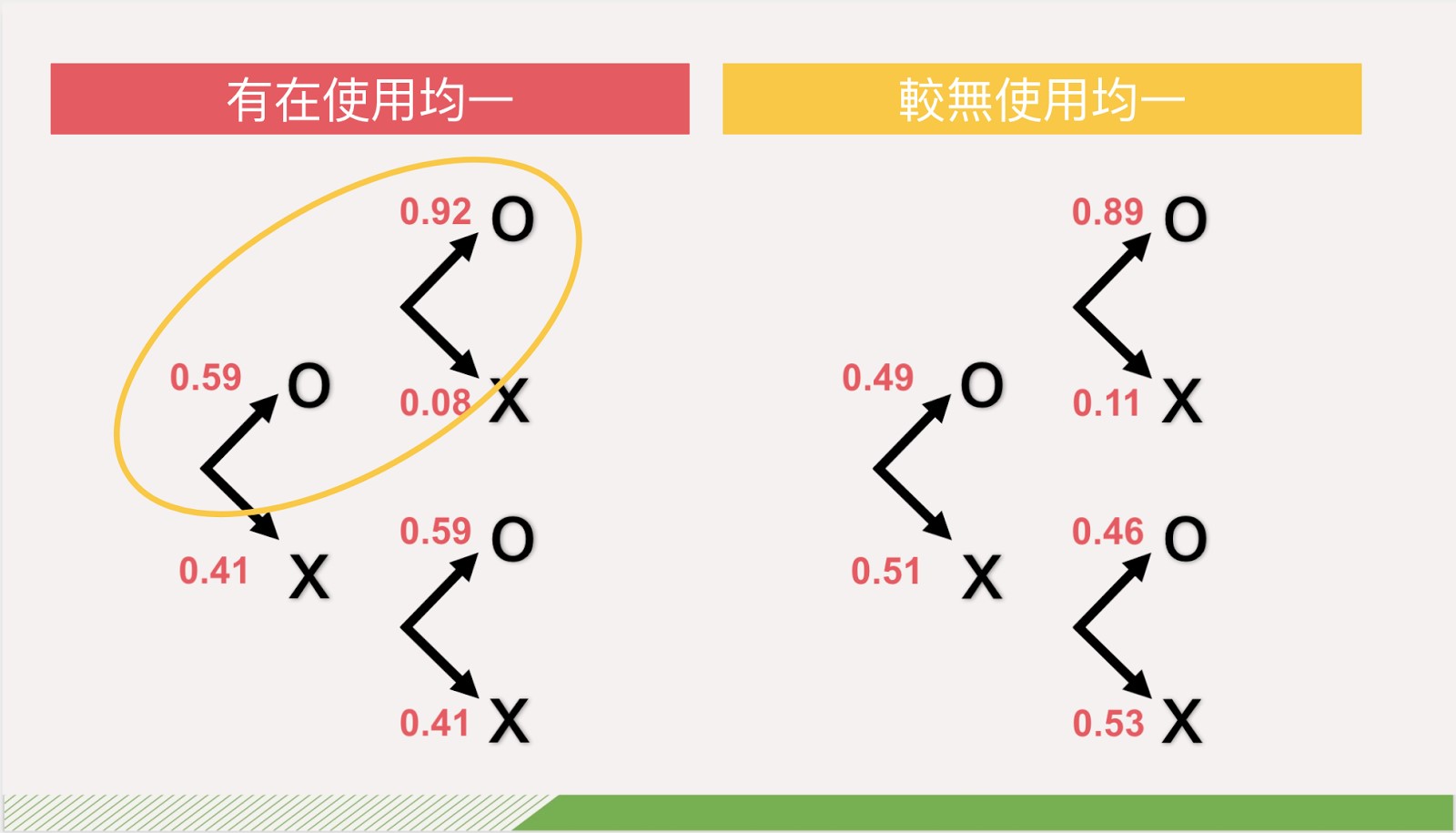
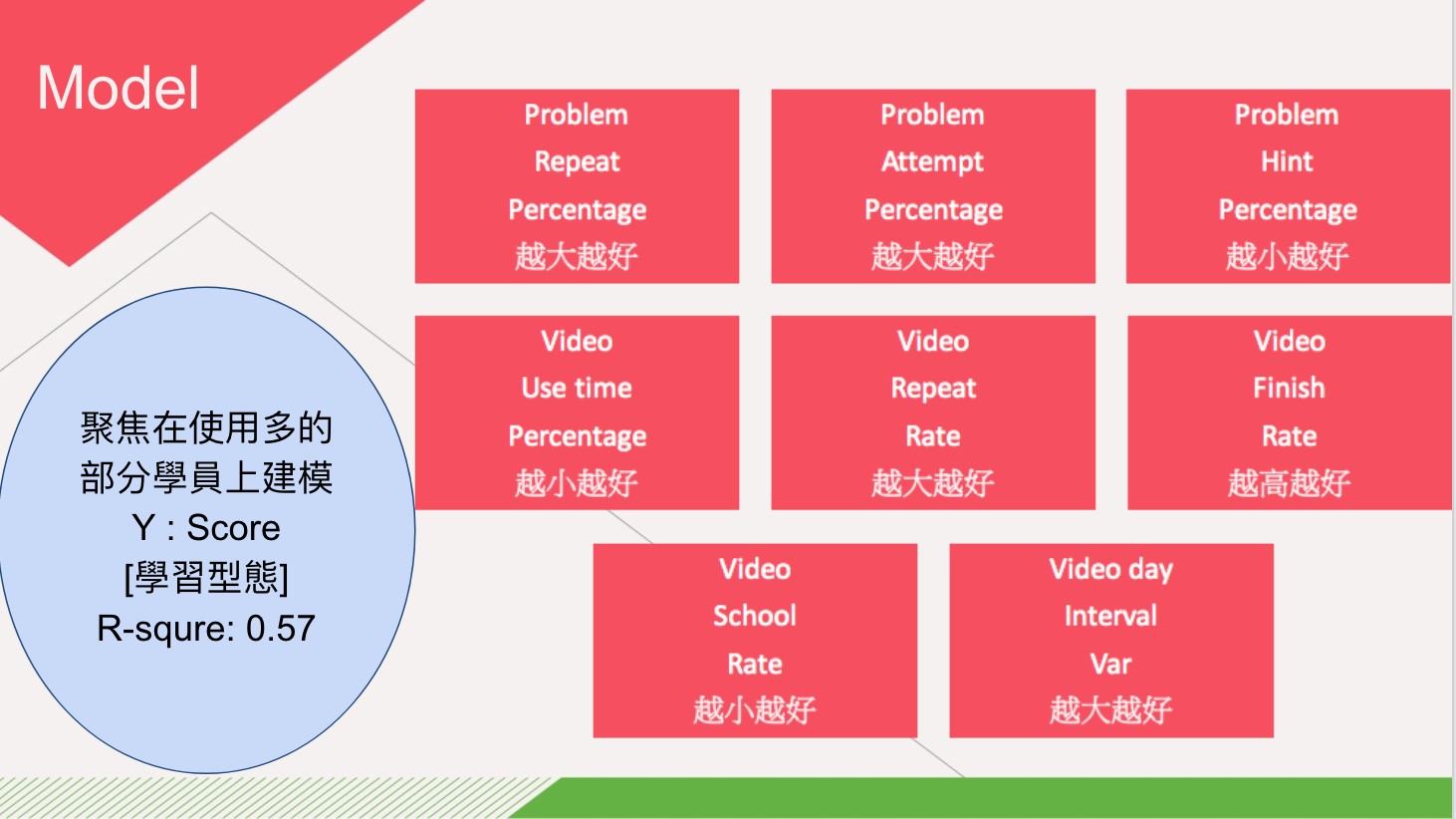
結論與建議
- 在整體趨勢來看,學生的成績是會隨著時間進步然而有認真使用均一的群體,在成績上會有更好的表現。
- 成績不佳之學員使用均一的比例不高,且仍有些學員很認真使用均一,但成績卻未有明顯的進步。
- 均一平台的設計,有些勳章的使用率很低,有可能反應了學員對於使用均一的興致程度。
- 均一對留住補救教學成績佳群體的能力較好,許多成績佳的學員都在兩次補救教學期間有定量的練習。
- 未來在「補救教學成績」齊全的情況下,可以再利用同樣方法進行比較,同時加入老師的行為特徵。
提案單位回饋
亂槍打鳥也要打對方向
ML方法很多種,每一種演算法都根據目標與資料型態決定,例如:這次用的「決策樹」就像是假設幾個方向有靶(跟Y有相關性),設法準備很多子彈(X變數),讓自動步槍(機器)幫我們發射,而不是自己拿著手槍一發一發的瞄準,這樣的好處在於有效率的節省時間,找出目標的幾種首要相關可能性,但這樣的方式也不是沒有風險,風險在於如果今天假設的方向錯誤,那麼就算將變數切到幾千種,也打不到對的位置,因此採用這樣的方法做研究時,必須同時有該領域的專家一起合作,在方向的設定上做初步的判斷,剩下的資料型態與工程面的部分就交給資料專家來進行,最後交給機器進行繁雜的運算即可。
人盡其才,物盡其用
組織內部過去在研究「指標」或是「預測」,常常會想利用領域專家或是資料專家直接開出規格,讓指標顯著,但我們知道我們的人腦無法一時間做太多層的關係構建,人腦較電腦擅長的是直覺,這樣的直覺是經由過去的學習及經驗而來,因此如果在科學研究上要利用直覺直接命中目標,其實很困難。
常見的例子有:我們利用幾個維度,將使用者分幾個層級,但是那幾個維度是我們自己想出來的,覺得「行為差異化」就是該如何如何,並將其計算出來,但其實我們並不知道設計的維度好不好,而且維度也很難再規模化,因為這樣的計算是用人力將程式編寫出來,進行自動化演算,一但維度一多,資料科學家就必須再根據維度的討論,寫出相對應的程式計算,充其量,這也就只是比較省力一點的「工人智慧」,因此,我們訂的題目要做出成果之外,也要記得均一的三不原則之一,不能擴大規模的事不做,在資料科學的技術上,也要小心不要讓自己在小規模的成功給限制住視野,要更進一步利用機器學習、深度學習的力量,幫助我們挖掘更多思考上的盲點,往真正的「人工智慧」更加邁進。
後續應用
基於這樣的想法,配合微軟提供的 azureML 服務或是 GCP,都可以讓我們在上面架設模型演算,因此 ( 教育推廣專家提供方向 + 資料科學家整理數據材料 ) x 機器計算,在機器計算這一點,經過這次的合作,提出心得,希望能幫助組織未來更妥善安排資料實驗。

Tag:資料英雄計畫
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021
