
高風險家庭資料建置與預警

Mentor:莊友欣、謝宗震
Project Manager:許瑋
Project Partner:財團法人漢慈公益基金會
社會變遷及家庭結構的改變,隔代、單親、外籍配偶及近貧等經濟弱勢家庭有逐年增加的趨勢。處於這種資源相對弱勢的家庭中,不僅課業無人指導,甚至下課後連晚餐也沒有著落。弱勢兒童及少年在成長過程中比一般家庭孩子要面臨較多貧窮風險。同時,主要照顧者因為本身照顧能力薄弱或多重角色負荷,甚難獨立承擔育兒及教養之壓力。
有鑑於家庭是個人發展重要關鍵,2008歲末,正逢金融海嘯席捲,原本就處於社會邊緣的經濟弱勢族群,影響更是首當其衝,許多家庭面臨失業、貧困的困境。在新竹科學園區的漢民科技公司,秉持扶助弱勢的使命,在風雨飄搖的2009年,成立財團法人漢慈公益基金會 ,結合當地清華大學、交通大學、新竹科學園區優勢的社會人文資源,無償為弱勢服務,提供「高關懷家庭支持服務」、「弱勢兒少生活陪讀」,免費提供課業輔導、品格教育、家庭關懷服務,藉由優勢觀點「與其給他魚吃,不如教他釣魚」自立理念,提升家庭復原力及韌性,進而恢復家庭功能。
建置高風險家庭的預測模型
在漢慈想要建置高風險家庭預測模型背後的想法,因爲在漢慈所輔導的家庭相對於一般政府機構更加的複雜和難處理,且漢慈在個案的輔導和幫助上是非常細膩的,從財務、法律支持、孩童教育上著手,往往需要課輔老師、社工、志工等一同完成,也因此有各式各樣紙本紀錄的資料。因此社工們在繁忙的情況下,往往還需要花很大心力去爬梳個案資料,得出一個全貌,尤其是對於初接案的社工,或是新手基金會夥伴,使得經驗不易傳承。
總結圍繞漢慈想要建置高風險家庭預測模型的相關問題:
-
如何使用這些記錄幫助漢慈裡的夥伴能更快速簡單掌握一個家庭的全貌,減少花費在翻閱紙本紀錄,且能由幾年來累積的資料萃取出一些經驗呢?
-
能否梳理漢慈夥伴們過去幾年的心血,設計一套高風險家庭的預警系統呢?
-
如何幫助社工們更方便的存取紀錄資料,以利往後進行資料分析,發揮資料的價值呢?
解決方案
專案開始是以建置高風險家庭的預測模型為出發,經過跟漢慈的夥伴討論後,評估三個月的工作時間和收集相關圍繞漢慈細節的問題,我們提出的解決方案包含一系列可以做的事情和優先順序。
- 整理漢慈內部所擁有的資料
- 挑選可以用來作為高風險家庭預測模型的資料
- 嘗試可能的分析方式來預測相關高風險家庭
- 將整個分析方案建置成完整的應用
資料描述
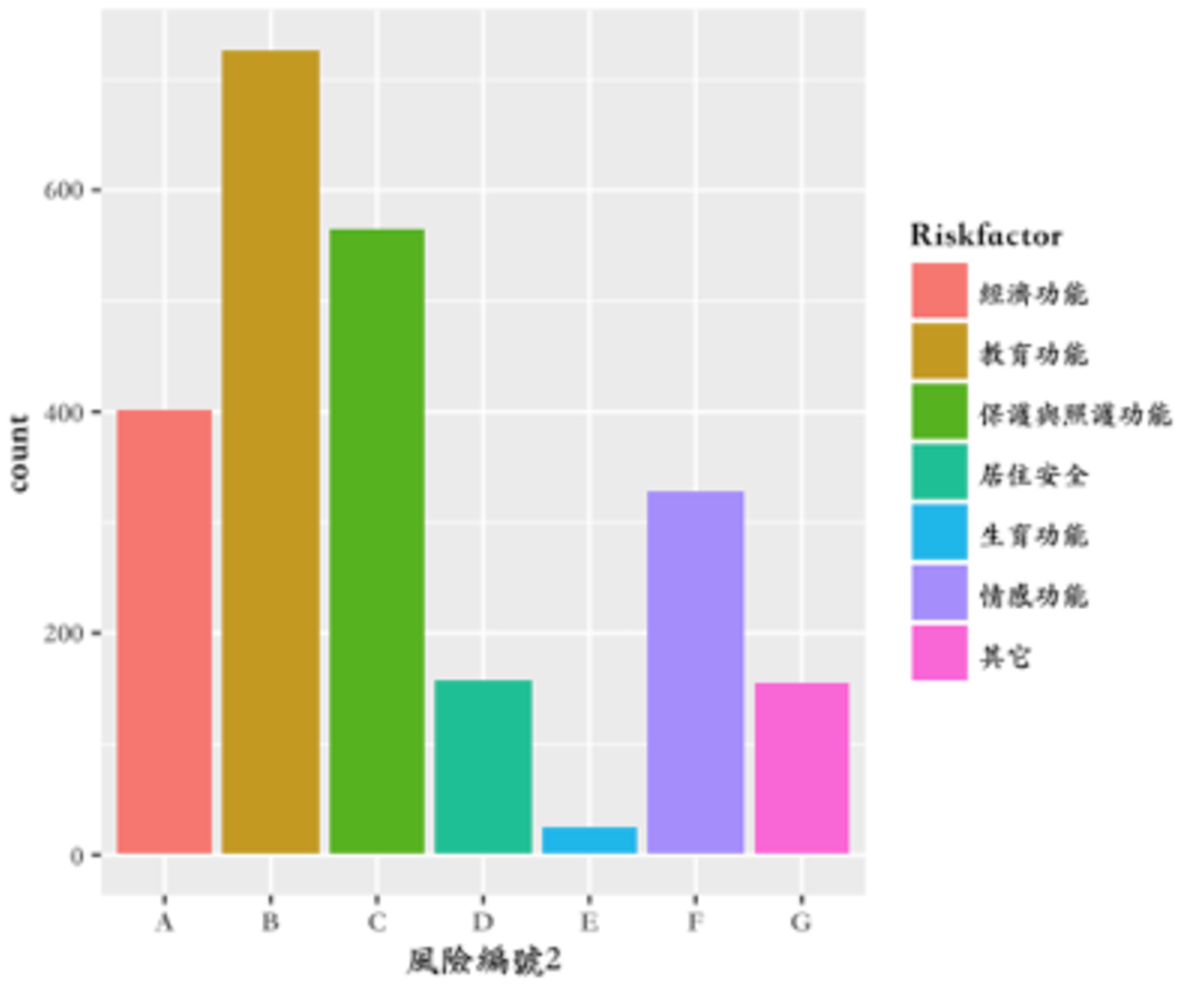
漢慈這邊提供的資料,主要有下面幾類:
- 個案的開案資料,共有78個個案
- 個案的家訪資料,共有46個個案
- 高風險家庭的風險因子對照表,共有7大類風險因子,分別代表家庭功能的各個面向
- 經濟功能:46個細項指標
- 教育功能:40個細項指標
- 保護與照顧功能:43個細項指標
- 居住安全:11個細項指標
- 生育功能:5個細項指標
- 情感功能:15個細項指標
- 其他:26個細項指標
分析過程
整個資料分析流程,我們一開始先請漢慈的夥伴讓我們理解整個基金會的運作和基本上在處理高風險家庭的過程,以及他們社工本身是如何判斷一個家庭有違和家庭功能出現的跡象,和平時基金會是如何追蹤他們的個案。基金會基本上有兩大方式來評估,第一部分是從家庭的基本結構來評估這家庭基本上的風險,接者在根據一到三個月不等的家訪來追蹤家庭的現況,所以我們最後決定使用個案開案資料和家訪資料兩個,嘗試能否從中推敲出用來預測家庭風險的因子。
資料清理
個案開案資料和家訪資料因為包含有個人資料,所以基金會這邊先去識別化,將每個家庭標號,去除掉姓名等敏感資料,資料格式基本上都是以word檔或pdf檔儲存,所以在前期處理會比較麻煩。
- 開案資料部分清理
- 開案資料內容為傳統的word表格,包含勾選的選項,在表格方面處理借為簡單,而勾選的部份因為全形和半形的關係,需要人工去檢查。
- 家訪資料清理
- 這部分的資料較為乾淨,為每個個案在特定時間家訪後,社工所標記的風險指標。
- 風險因子指標
模型建立的策略
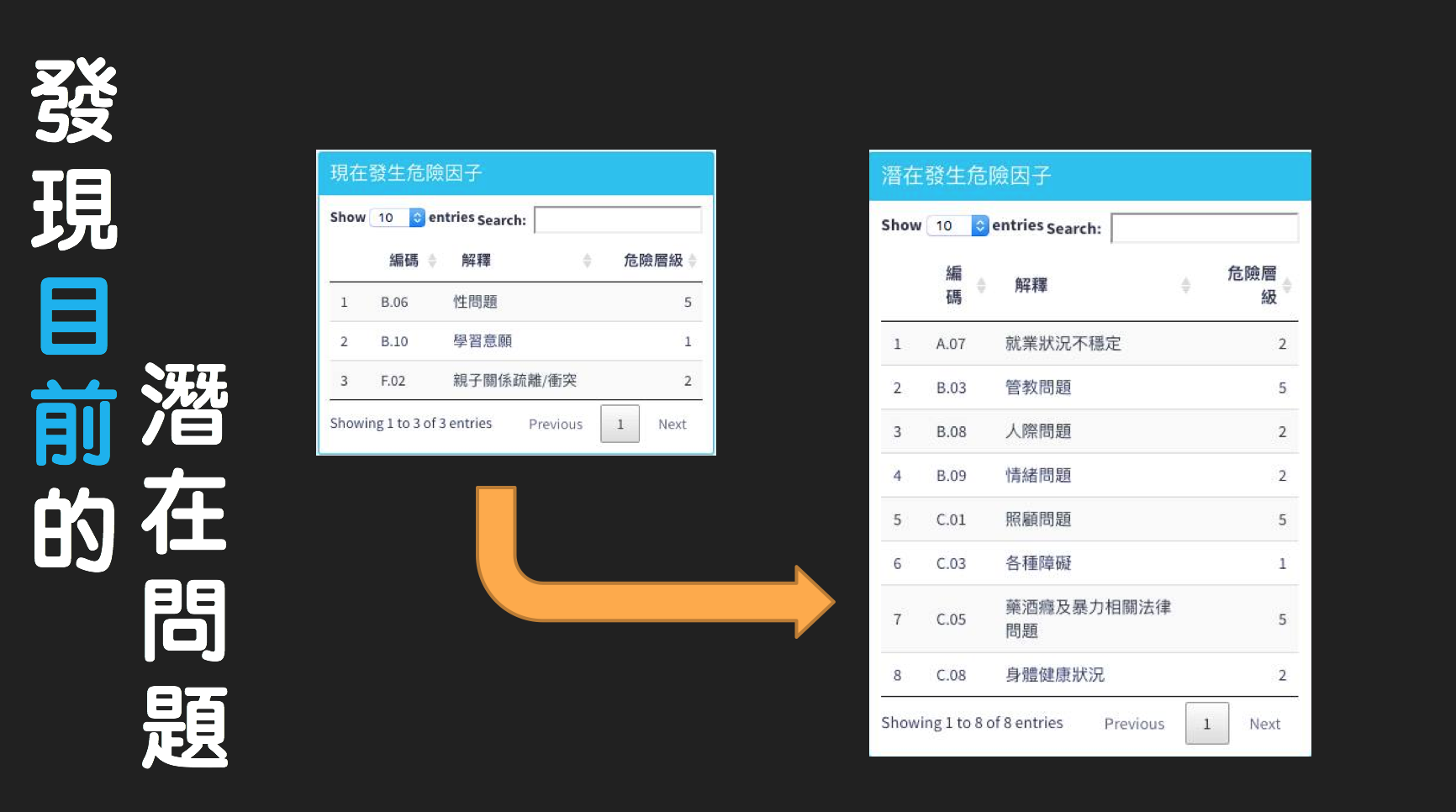
經過整體瞭解後,發現基金會已經先用人工的方式標注每個家戶在不同時間下家訪後,社工評估,使用基金會建立的風險指標來標定,但實際上,沒有一個風險高低的預測目標,所以經過討論後,希望是可以預測出家戶是否會發生「家暴」、「性侵」、「吸毒」及「偷竊」事件,以及能給予出一個風險值,所以後續再請基金會去開案資料標記哪些家戶有發生上述四大危險事件,以及分別把每個風險指標給出高、中、低三種風險值。
探索性分析
我們先分析看是否不同風險因子種類在數量上的分佈,以及看七大風險因子類別的各細項風險指標的統計資訊,在不同風險指標數量上的分佈,以教育功能這類指標在家戶中被判斷發生問題的頻率最高,而在生育功能這項指標上發生問題的機率最低。
關聯性分析
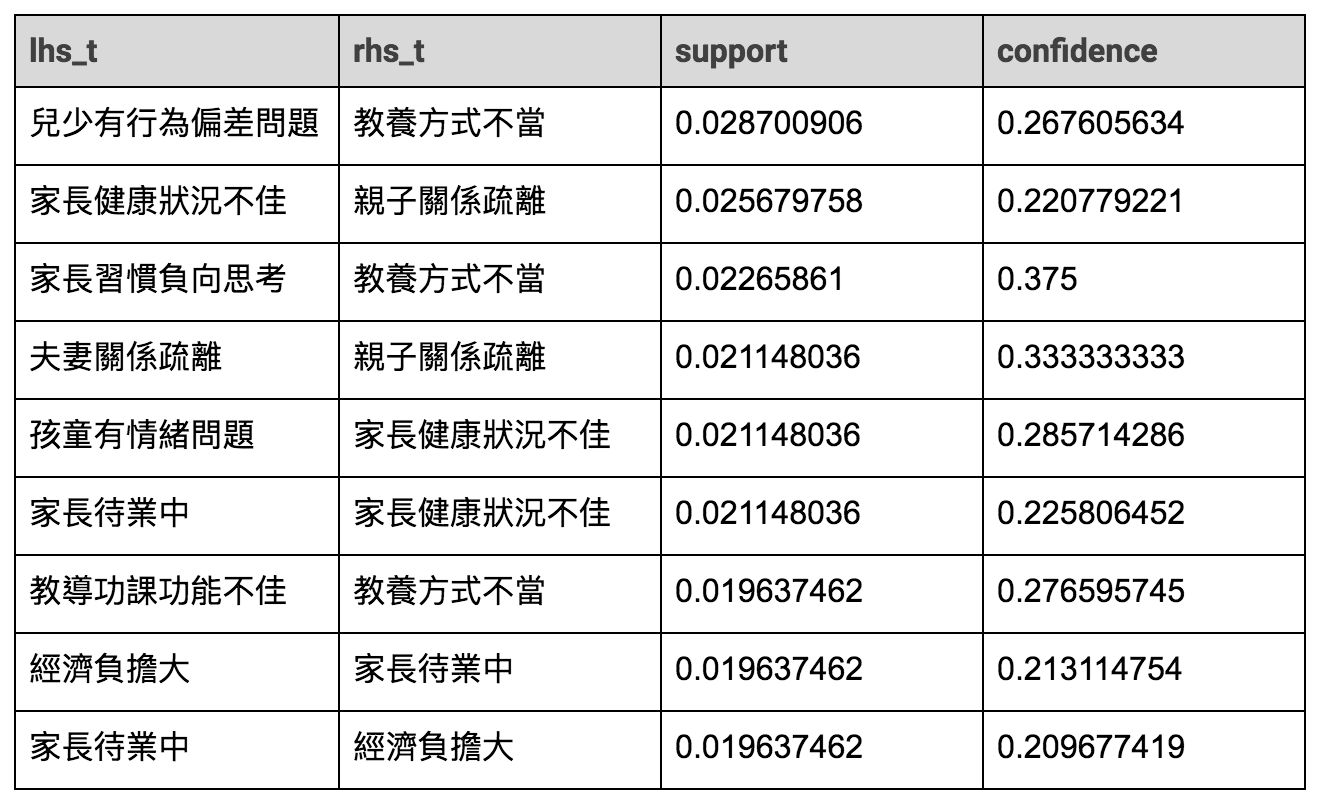
經過探索性分析後,其實發現這些風險因子的分佈,很難看出什麼規律,所以我們嘗試使用關聯性分析來看是否有什麼風險因子是常常一起發生的,關聯性分析其實就是常見的購物籃分析,其實就是藉由頻繁模式探勘來找尋資料中的資訊,用此分析方式主要看兩大指標,支持度(Support)、置信度(Confidence),來判斷風險因子間的關連性是不是很強,支持度主要是看兩個風險因子一起出現在資料中的頻率,置信度則是看兩個風險因子本身是否頻率的差距很大,避免錯誤歸因。
可以將我們分析出來的關連性關係視覺化出來,因為其實就是兩個風險因子的關係是否常出現,用此總結出一條條的規則。
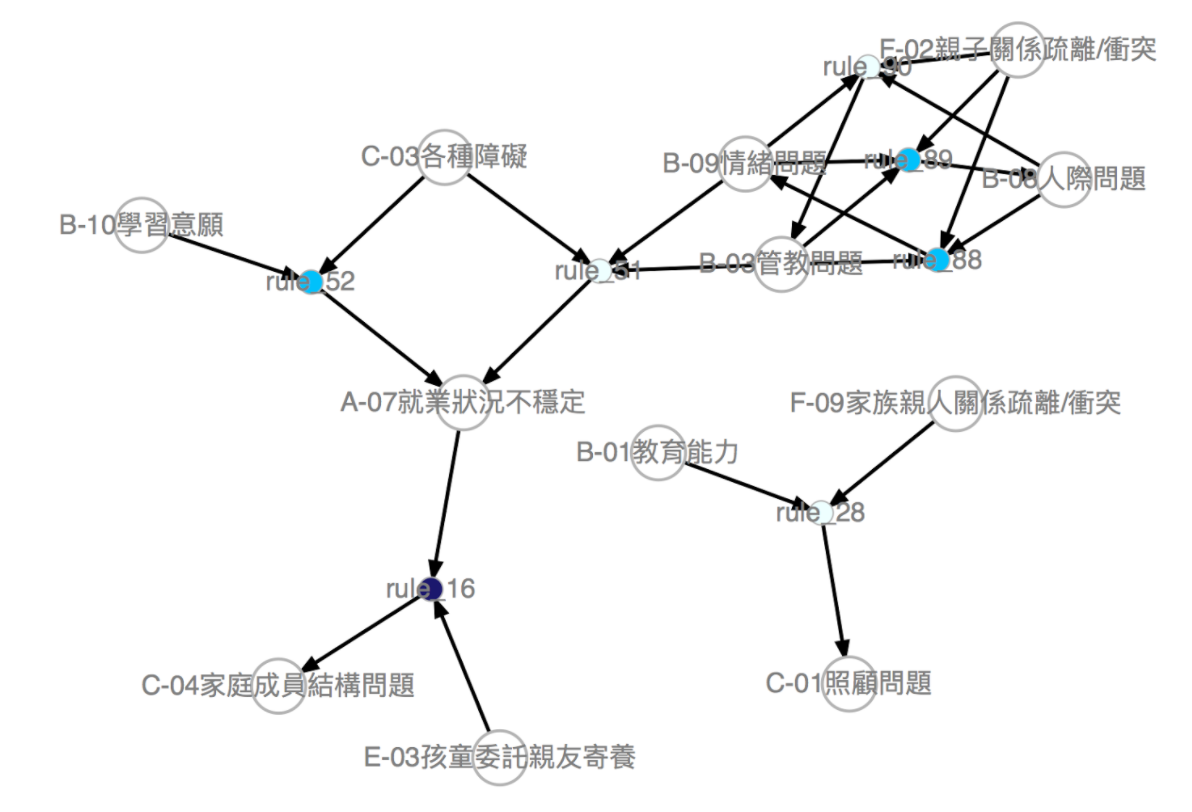
從我們的資料中,可以找出大約 300 個支持度在 0.05 以下的關聯,再經由跟漢慈基金會的夥伴討論,刪減成比較合理的組合,並且把一些因為詞彙上相近不好分開的規則去除掉。接者便可以利用這些規則來幫助用來預測可能的潛在風險因子。
馬可夫鍊分析
馬可夫鍊的分析主要是為了建立各個風險因子的發生預測模型,主要用資料中每兩次家訪間的資料來建立機率值,主要用來預測單個風險因子其持續發生的機率和單個風險因子下次不再發生的機率,和原本沒有的風險因子在發生的機率。最終將這些資料跟前面的關聯性分析結果相互搭配。
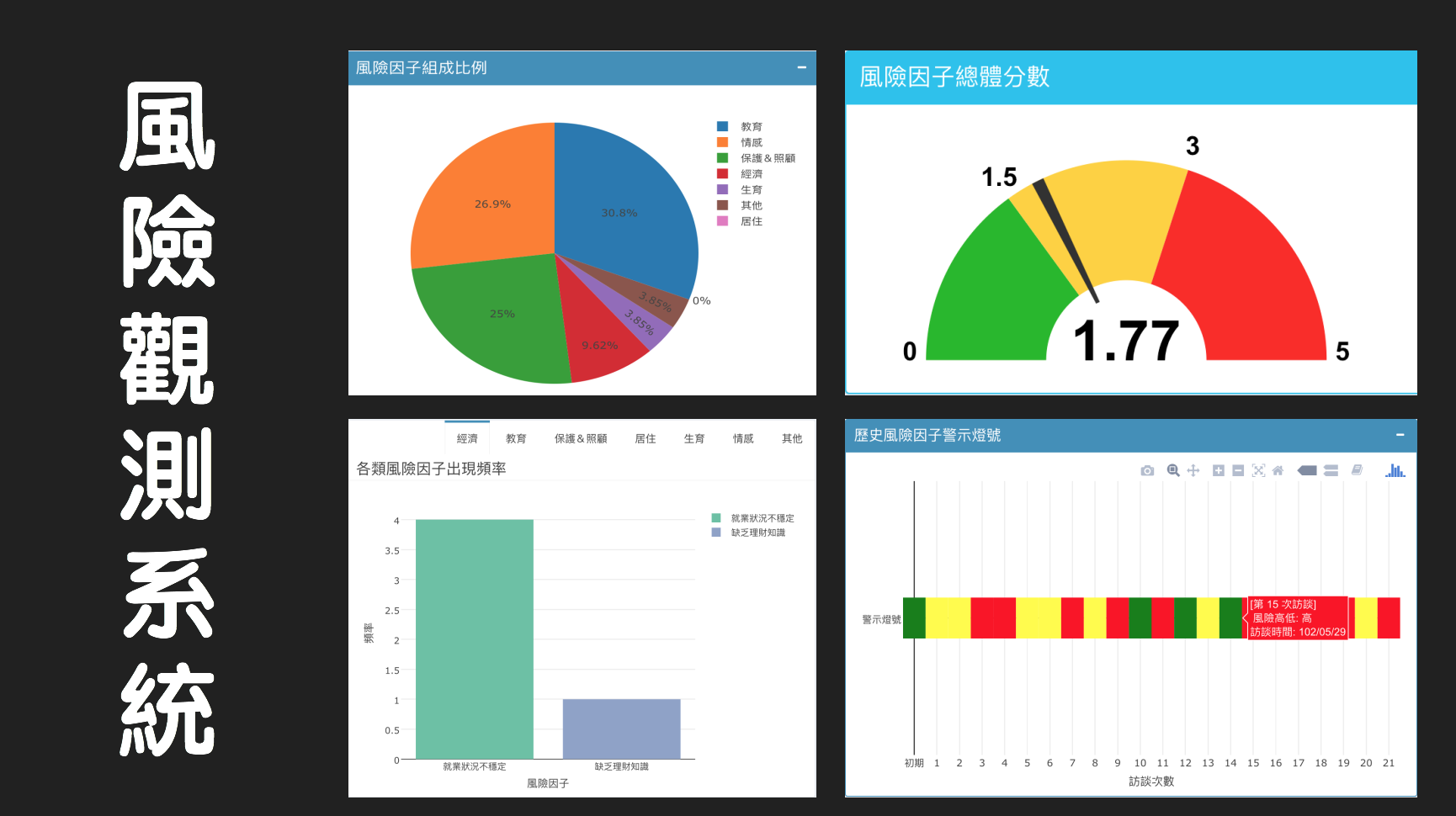
風險值警示整合分析
另外,根據漢慈基金會後來有把每個風險因子分成高中低三種,我們分別給予高中低一個數值,最後可以根據每個人當下的風險因子來給予一個如紅綠燈般的數值表,能一目了然目前風險狀態。
最終成果
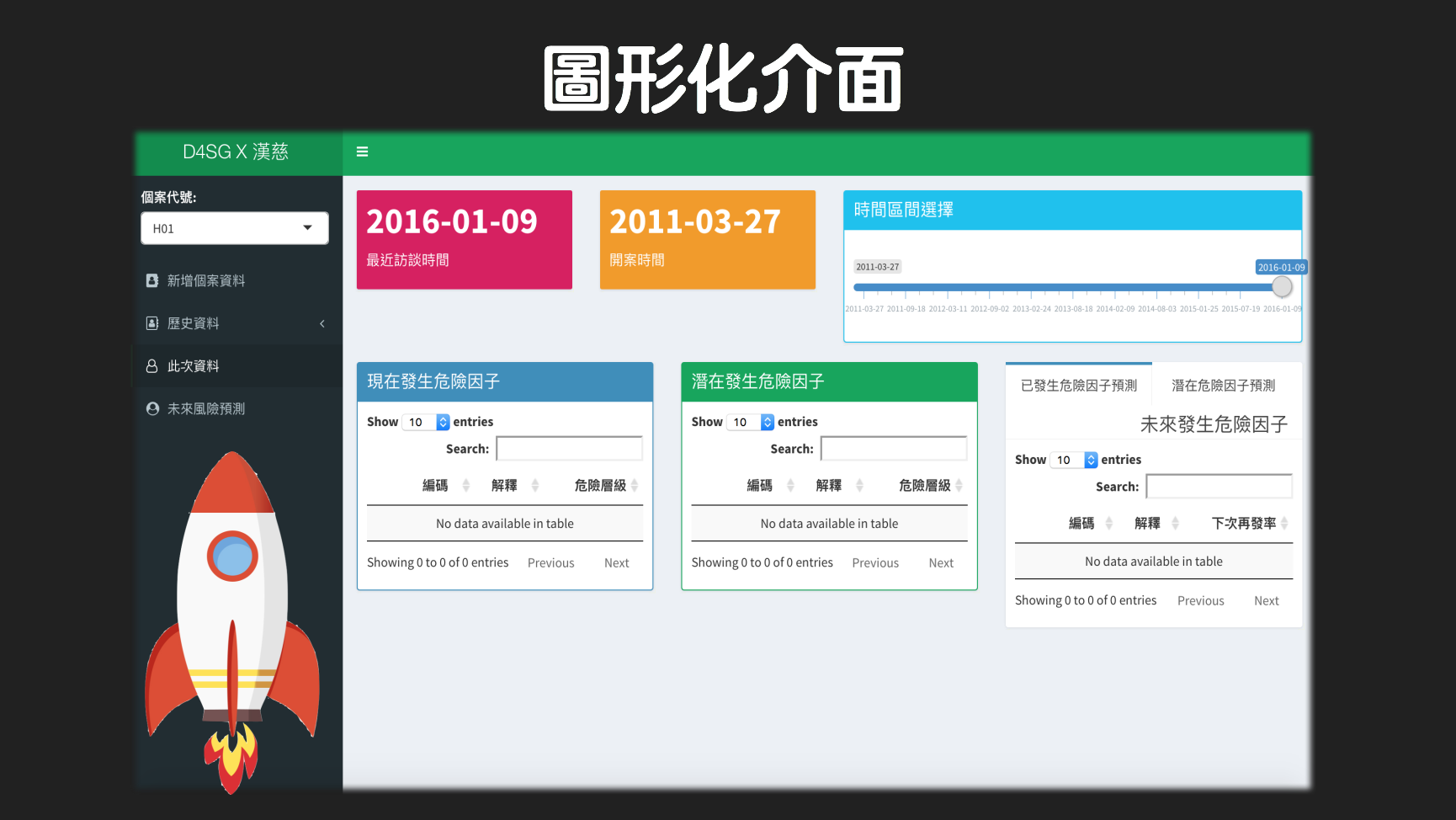
最後把所有功能整合到一個應用程式之中,分別三大部分呈現,第一部分是基礎的統計資料分析和呈現,第二部分是各個風險因子細項的呈現工作,第三部分是用馬可夫鍊和關聯性分析建立的模型來對單個家庭個案作分析,最後新增了上傳的功能,這樣就除了建立高風險模型預測外,一併解決了漢慈基金會在基礎資料工程的問題。
應用的程式主要可以由下面的截圖來看實際操作之樣子。
討論
資料處理實際上是這次專案花掉最多時間的地方,因各處室資料格式繁紊不一,資料整併窒礙難成。冀望將來,市府能將跨處室之集中資料倉儲作為資訊基礎建設之基石。
Thank You for Being Late – 湯馬斯.佛里曼
當市場全球化、氣候變遷、科技進展,這三股力量同時撲面而來,過去經驗已不再全部適用,成功法則全數崩解。
大數據浪潮的席捲之下,在國外跨領域的資料科學應用被奉為解決公共難題的聖杯。在台灣,社會工作者面對需求多元化、問題複雜化,全球化新興議題,很難根據服務對象的訪談記錄和其他服務資料,彙整服務對象問題成因及議題的樣貌,然後決定是否提供干預。所以當我們用資料科學來幫助建立高風險家庭的模型,一方面可以幫助社工人員更系統性地管理日常工作,另外一部分,可以更好的分配有限之補助資源。
當然,這過程還有許多待解決的難題,其中一個就是需要獲得傳統社工們的支持,畢竟部分社工們對於用資料科學來處理複雜的家庭評估還有很多疑慮,如何加入社工們專業的意見是接下來很重要的議題。

You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021
