
火災火警報案資料探勘

Fellows:曾凱聲、張凱鈞、宋培源、王宜婷、許筱翎、韓鈺瑩
Mentor:謝宗震、劉嘉凱
Project Manager:王蕙盈
Project Partner:高雄市政府消防局
對抗火災的最佳策略是採取預防性攻擊,防患於未然。若用資料科學的語言描述,就是定義問題、資料盤點與清理、分析建模、預測、決策支援。
以高雄市為例,每年的火災案件不到一百件,但是消防隊員還是忙不完。有一個重要的原因是,雖然每年「火災」數量不多,但是「火警」的案件卻是數以千計。火警和火災,差別只在一線間。家中瓦斯爐燒開水未關,鄰居報案後,消防隊來得及破門而入關掉瓦斯,就只是火警;來不及關掉,就可能演變為造成生命與財物損失的火災了。而不論火災或火警,其危險因子(例如起火原因、建築物特性、人口特徵等等)可能都是共通的,若能評估火警風險,或許就等同建立了火災風險模型。這即是 D4SG 資料英雄計畫「火災風險地圖」專案正在設法解決的公共問題。
我們是一群「用資料力做公益」的資料英雄,很榮幸與高雄市政府消防局合作,利用週末和晚上,共同分析過去數年的消防案件,從無到有,開始打造台灣第一個「資料科學,打火救人」的實戰經驗。
高雄,加油!
資料來源
1. 高雄市政府消防局火災紀錄資料
2. 高雄市政府消防局火災分析表
3. 高雄市政府消防局火警出動人車數
4. 高雄市政府消防局各大隊補助安裝住宅用火災警報器場所清冊
5. 高雄市政府社會局資料(低收入戶、獨居長者、身心障礙)
6. 高雄市政府稅捐處建築物資料
問題解決
一、人力配置
問題
如何使人員排班更有效率?(每個分隊在什麼時段可精簡人力,什麼時段須要多加派人力?)
高雄市政府消防局每個隊員的值班待命時間為早上8點到隔天9點,共25小時。
若能從歷年的火災紀錄看出忙碌的時段差異,在較不忙碌的時段安排較少的人力,在滿足基本戰力與鄰近分隊即時支援的前提下,不必讓每個隊員皆值勤25小時的時間,能夠讓隊員有更多時間休息,避免不必要的人為疏失,並作更有效率之人力配置。
分析
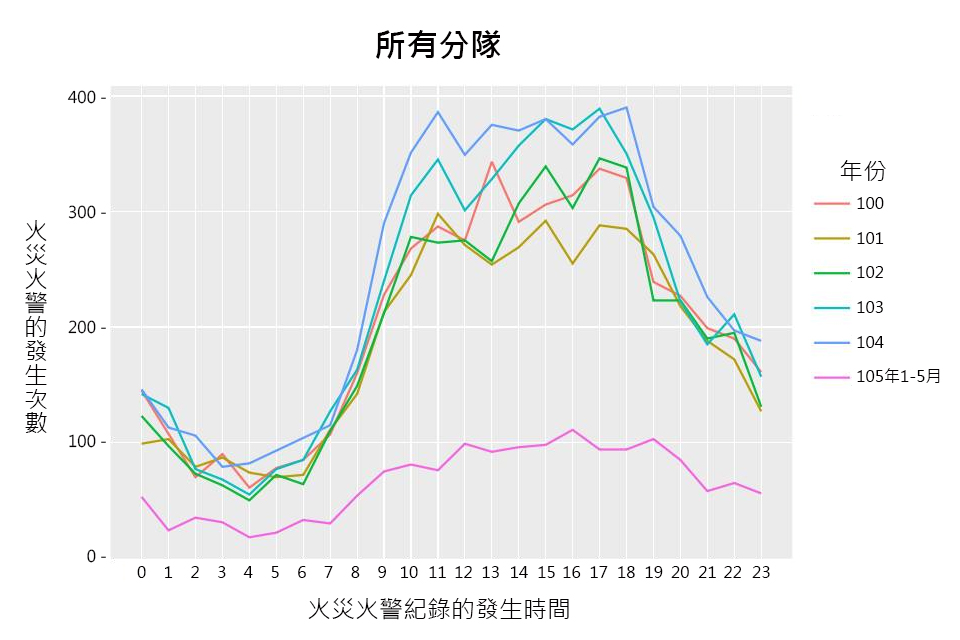
1. 以派遣次數的角度出發:
分隊的派遣次數越多代表該時段火災火警發生越頻繁,消防人員出動的次數越多。以線圖呈現分隊忙碌的時段。使用分析欄位:案件時間、派遣分隊、案件狀態。
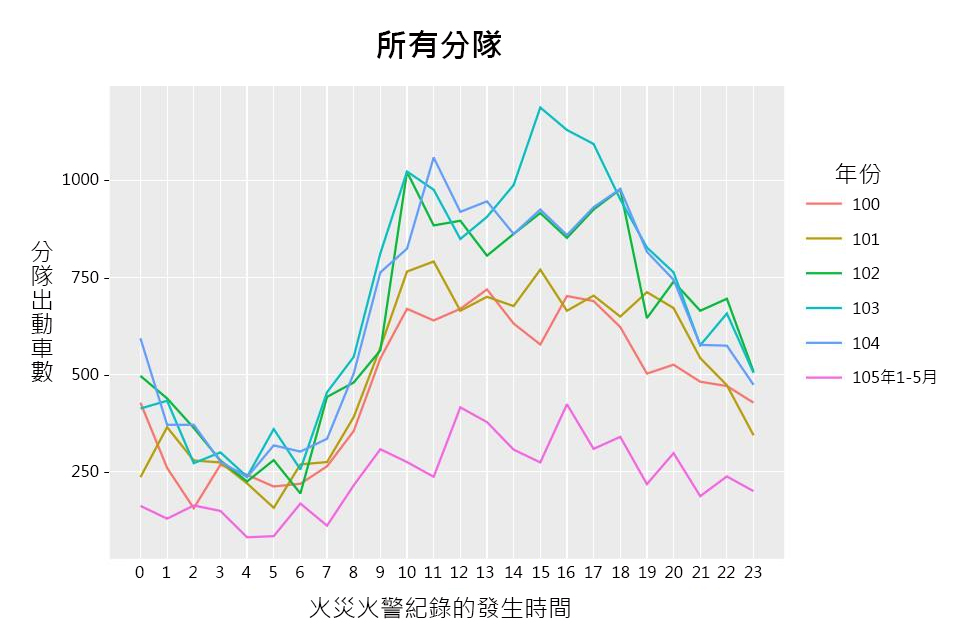
2. 以出動車數的角度出發:
出動車數越多代表該時段該分隊除了必須處理很多火警火災的報案之外,棘手的案件也較多。以線圖呈現分隊車輛出動情形。使用分析欄位:案件時間、出動車次、案件狀態。
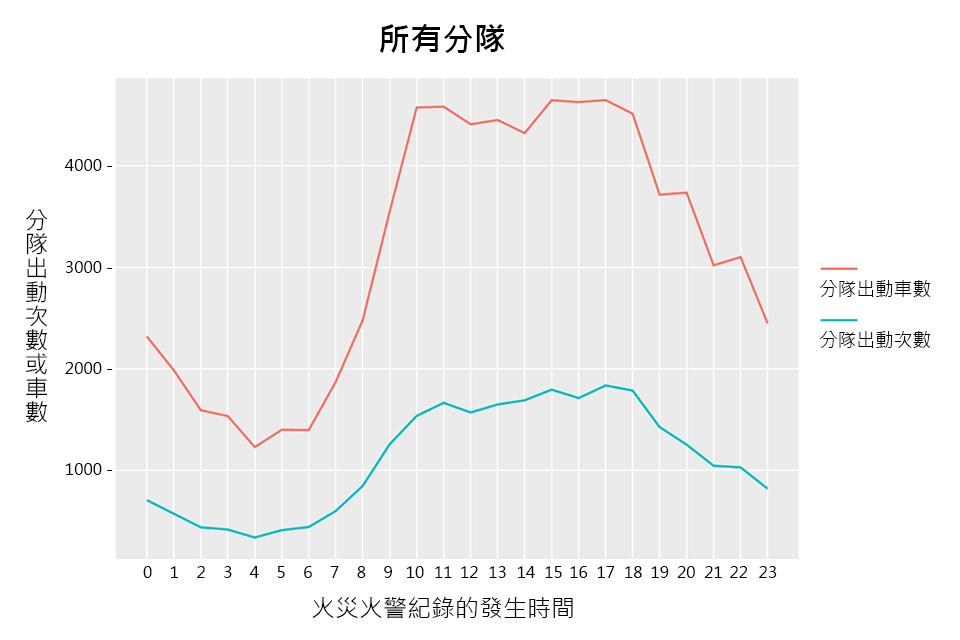
3. 派遣車數與出動車數做比較:
經由派遣車數與出動車數一起做比較的話,可以很容易地看出哪些時間點是分隊出動頻繁且又需要較多人手的時候。
分析結果
經由上述圖表可以發現分隊在不同年度、月份與時間的出勤忙碌情況,日後可以參考曲線趨勢進行人力的機動配置。
二、住警器發放
問題
「住宅安裝住警器、家人安全有保庇」,這是消防局宣導安裝住宅用火災警報器(住警器)的標語,安裝住警器以降低災害的嚴重性。消防局每年都有收到善心人士捐贈的住警器,而消防局面臨到的問題是,如何發放這些愛心住警器,得以讓社會發揮出最大效益。
分析
我們觀察各區里的火災風險指標,探討過去幾年的發放情形,在各區里的發放比例上,是否有其他的改善空間。
1. 資料蒐集
(1) 高雄市消防局住警器發放列表
(2) 高雄市火災警資訊 [消防局]
(3) 高雄市弱勢族群(身心障礙、獨居長者)資訊 [社會局]
(4) 高雄市建築物資訊 [稅捐處]
2. 住警器發放指標
指標設計目的是希望透過簡單的分數高低,去理解高雄市各個區里發放的狀況,將有限的資源,做妥善的發放以達效益最佳化。
每個指標的分數,都是將原始數值標準化後(重新將級距放縮為0到100之間)的結果,因此不同指標間的分數,是可以相互比較的。指標公式如下:

◆ 住警器申請數量分數:
統計各區里已經發放的住警器申請數量,並將原始數值標準化,分數越高,代表發放數量越多。
◆ 風險分數:
在火災機率成因檢定中,藉由建立統計模型,去預測每個區里發生火災的機率,並將機率標準化,分數越高,代表該區發生火災機率越高。
分析結果
由上述發放指標分數資訊,我們可以得到各區里現狀的住警器涵蓋分數,呈現如下方地圖,若某區里指標分數大於0(地圖上顯示藍色),則代表住警器發放情況過剩,反之若某區里指標分數小於0(地圖上顯示紅色),則代表住警器發放情況缺乏。若未來消防局欲發放愛心住警器時,可利用上述資訊來調整各區里發放數量的比例,以達到效益極大化的目的。
▼ 住警器發放指標地圖
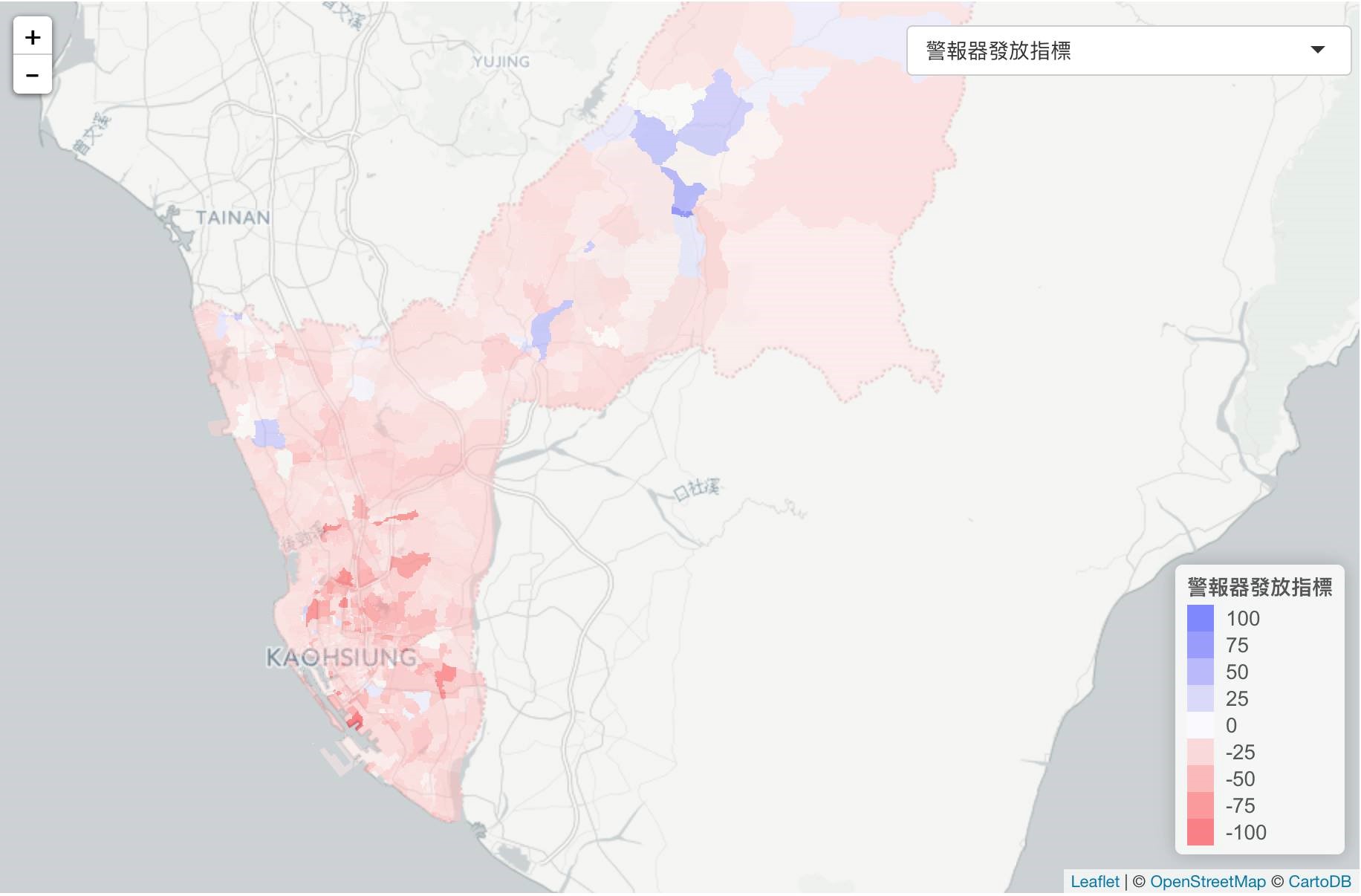
▼ 分數最高為六龜區-義寶里
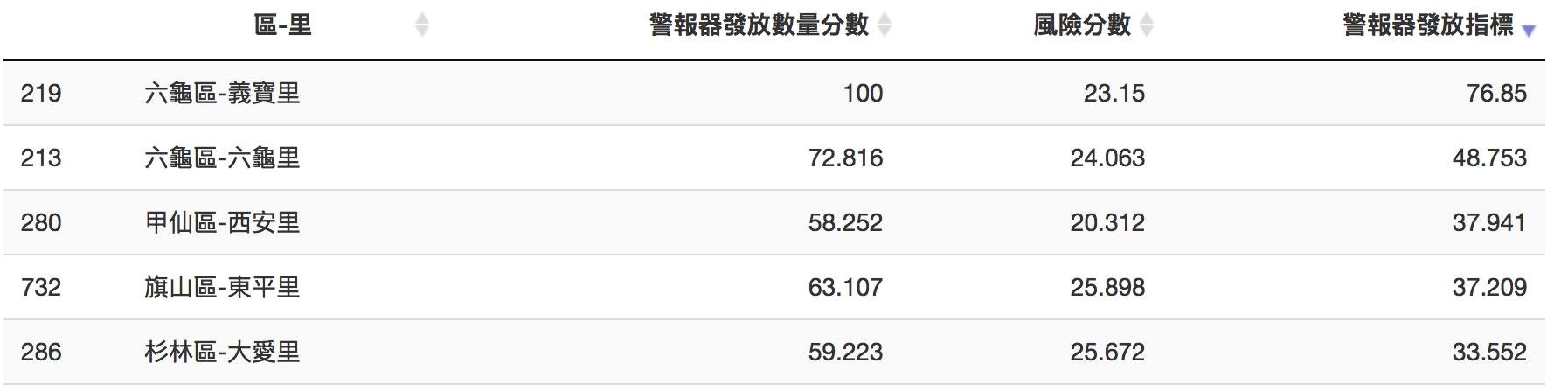
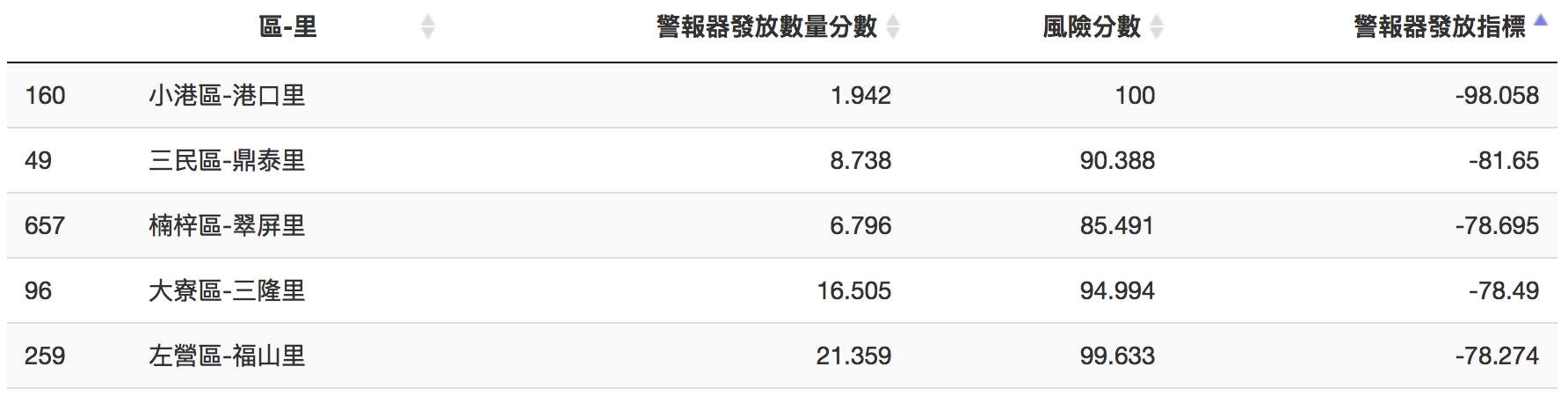
▼ 分數最低為楠梓區-翠屏里
三、火災火警發生原因
問題
高雄市消防局想了解高雄市地區火災火警真實發生原因為何,並藉由發掘此原因以提供對市民最有效的防災與預防措施,進而讓高雄市火災火警風險降至最低,讓市民生活在一個安全無虞的環境中。
分析
藉由高雄市消防局所提供的資料,包含地籍資料、火災火警發生時間/原因/場所,以地區做整合,提供出一個初步的資料庫,並從中取得我們想要的資訊。
1. 火災火警主要成因
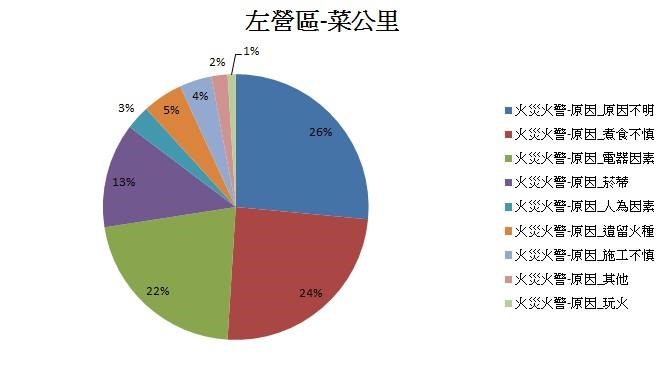
利用整併後資料庫,將高雄市所有火災火警的數量對火災火警成因作圖,我們可以發現主要Top3造成高雄市火災火警成因為 「原因不明」、 「煮食不慎」、 「電器因素」。(註:「原因不明」為沒有紀錄或顯示原因待查)
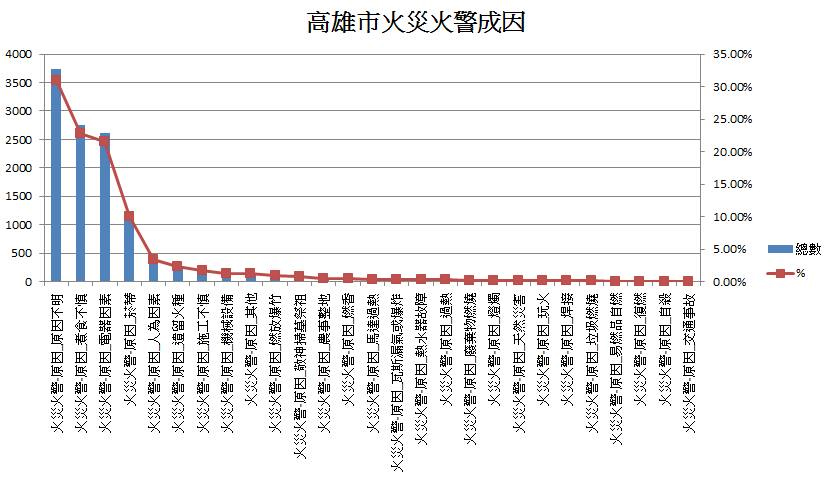
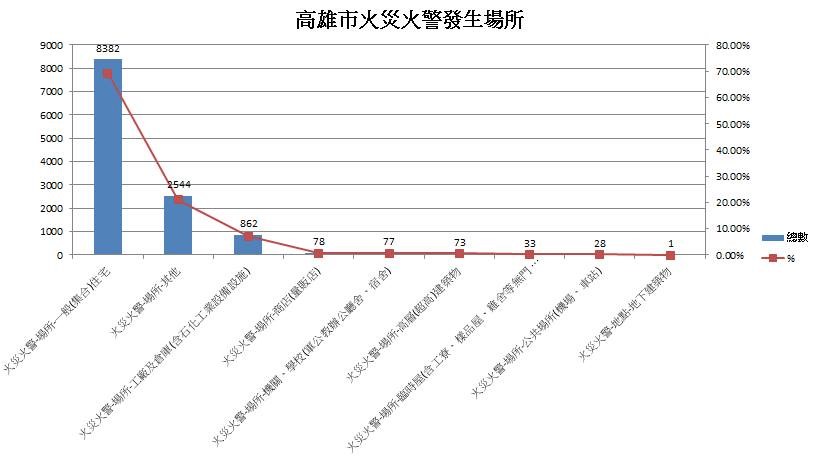
2. 火災火警主要場所
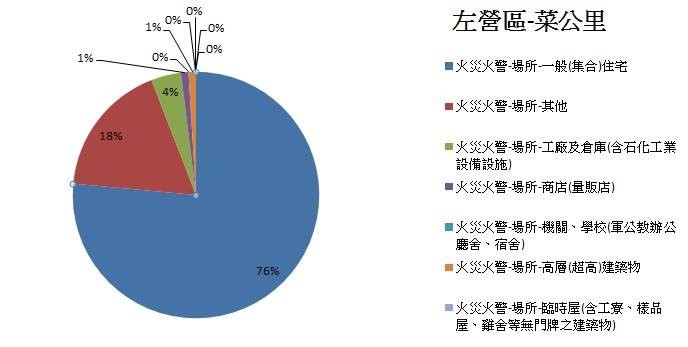
利用整併後資料庫,將高雄市所有火災火警的數量對火災火警發生場所作圖,我們可以發現主要Top3造成高雄市火災火警場所為 「一般住宅」、「其他」、 「工廠及倉庫」。
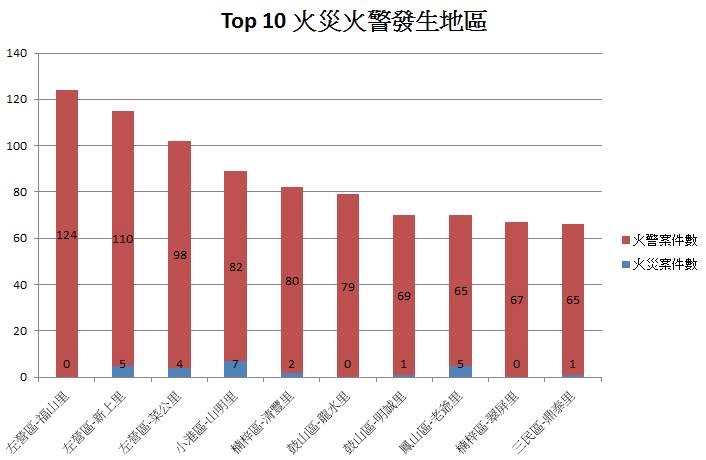
3. 火災火警主要發生地區
將高雄市所有火災火警的數量Top 10的地區作圖,我們發現左營區佔前三名,分別是「福山里」、「新上里」、「菜公里」。
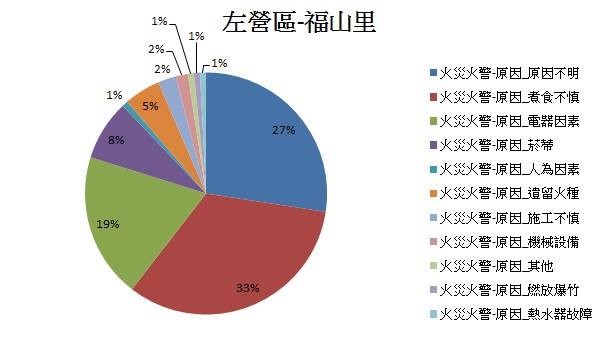
4. 將左營區前三火災火警數量做細部觀察
▼ 左營區福山里 – 成因
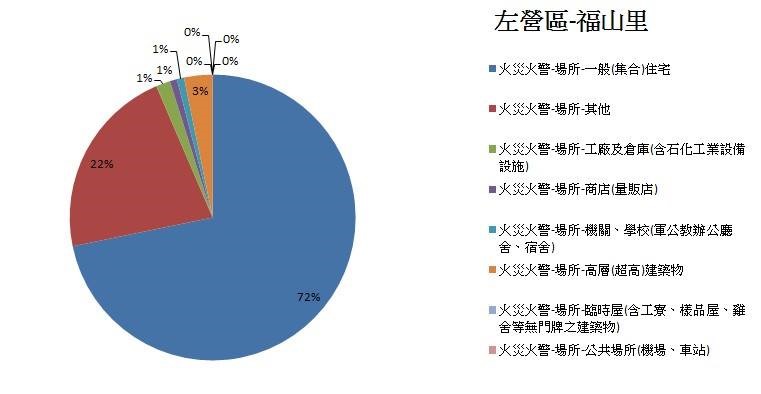
▼ 左營區福山里 – 場所
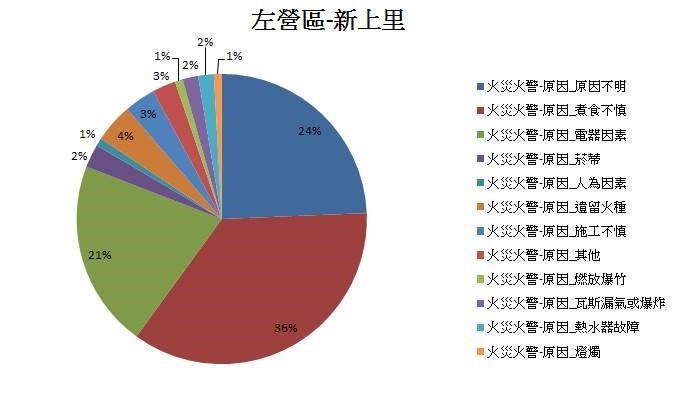
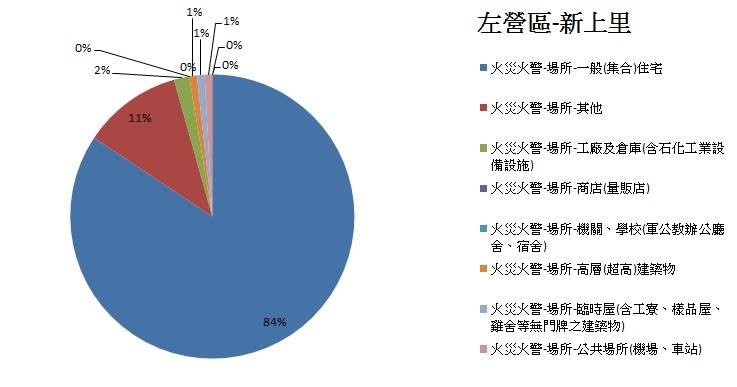
▼ 左營區新上里 – 成因
▼ 左營區新上里 – 場所
▼ 左營區菜公里 – 成因
▼ 左營區菜公里 – 場所
分析結果
由上述分析得知,高雄市整體火災火警主要是發生在住宅中的「煮食不慎」以及「電器因素」,以及在紀錄上原因較難辨別的項目,另外,發生最多火災火警的區域為左營區的三個里(福山里、新上里、菜公里),且其火災火警成因前三名也是煮食不慎、電器因素與原因不明。
此外,我們也提供了互動式地圖查詢:
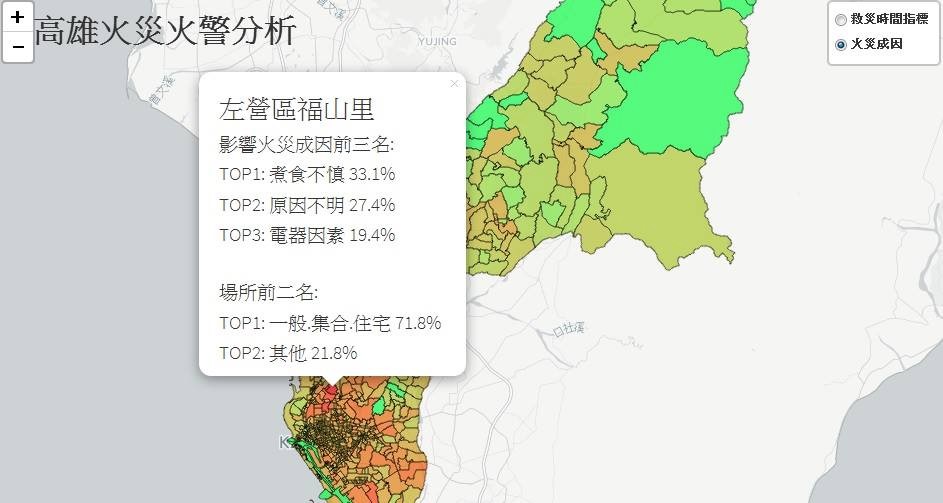
藉由高雄市消防局所提供的資料,加上開放資料中的區里界圖資訊,將火災火警發生次數以熱圖方式呈現,紅色越深代表該區火災火警發生次數越多,反之綠色則是次數較少區域,並提供各區里火災火警成因前三名以及發生場所前兩名,方便使用者查詢各區域狀況,制定符合各區域最有效率的防範火災火警方法。
四、火災機率成因檢定
目的
利用統計方法,針對身心障礙、獨居長者及房屋資訊這三大類變數,預測風險機率值。探討此三大類變數對於預測風險機率值的變數顯著性。
資料準備
1. 風險指標選取
由於是探討此三大類變數與成災的相關性,故將風險機率值定義為發生火災的機率。
詳細定義為,若此區里曾發生過火災,則將此區里定義為「發生過火災的區里」,否則相反。並將此問題對應成為一個分類問題,將891個區里做分類,並預測會屬於「發生過火災區里」這一類的機率。
2. 變數選擇
變數來源有三大類,分別是身心障礙、獨居長者及房屋資訊,並為避免解釋上的困難,選取較具代表性,且較適合定義的變數來進行預測。
選取的變數有身心障礙-嚴重程度-中度、身心障礙-嚴重程度-重度、身心障礙-嚴重程度-極重度、身心障礙-嚴重程度-輕度、身心障礙-人數、獨居長者-平均年齡、獨居長者-人數、房屋資訊-透天住戶數、房屋資訊-大樓住戶數、房屋資訊-工廠個數、房屋資訊-平均屋齡、房屋資訊-住家用面積平均、房屋資訊-營業用面積平均。
模型建立
1. 模型選擇
由於要做的是分類問題,並且需要衡量各個變數對風險指標的影響程度,因此選用邏輯斯回歸(Logistic Regression)來進行分析,並搭配逐步回歸(Stepwise Regression)的方式來挑選對風險指標預測有顯著效果的變數。
2. 建模詳細過程
將891個樣本平均分為十組,並使用分層抽樣(stratified sampling),考慮每一組有火災紀錄的樣本比例,約略和所有樣本的火災紀錄比例相同。
取第一組為例,將組一的樣本當作測試樣本,其餘九組樣本當作訓練樣本,利用九組樣本的資料建立一個逐步邏輯斯回歸模型,並將建立好的模型儲存,去預測第一組樣本,已得到第一組各個樣本的風險機率值,此值越高,在代表發生火災的機率越高。重複此步驟,對第一組到第十組都用相同的方式建模、預測。
3. 模型評價
在建立任何一個模型時,會訂定一個數值作為此模型的評價指標。以下分為最終模型評價與逐步過程評價:
◆ 最終模型評價:此處選用ROC曲線下面積(AUC)來作為評價指標,若此指標數值大於0.5,則代表模型具參考意義(亂猜的結果是0.5)。
◆ 逐步過程評價:此處使用AIC來作為逐步過程評價,隨著每一次逐步回歸的結果,希望讓AIC越來越小。
建模結果
1. 模型成效
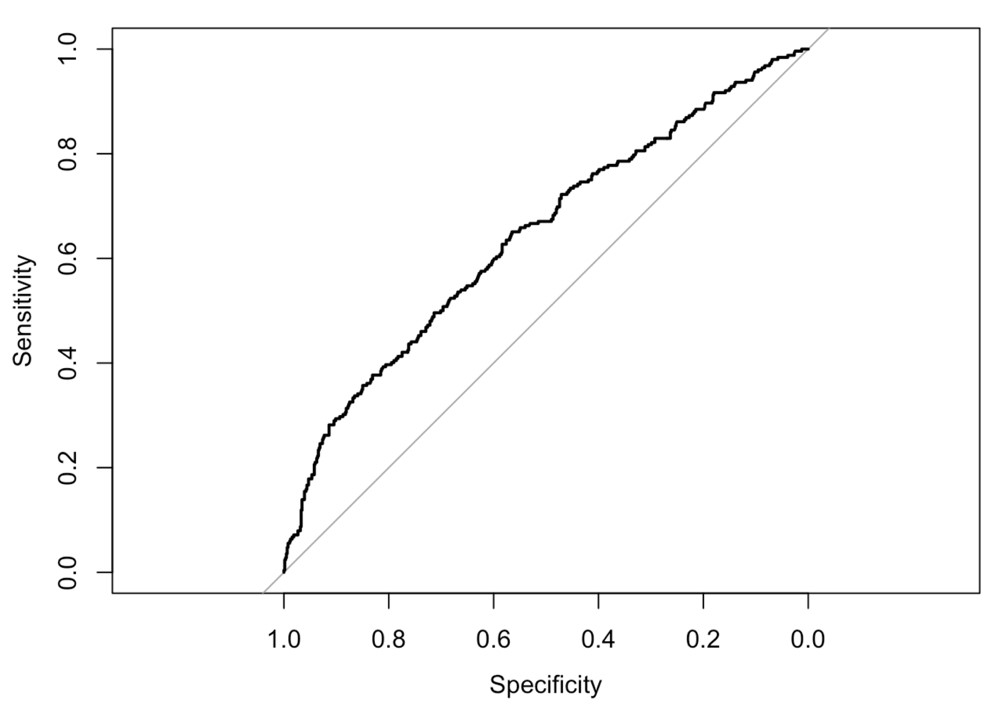

第一張圖型為ROC曲線,圖中的灰色對角線為基準線,若畫出的ROC曲線在此基準線之上,則代表此模型的結果具參考意義。由圖形可看出,此模型結果比隨機亂猜的結果來得好。
接著由輸出的最後一行可以得到Area under the curve: 0.6428,代表AUC為0.6428,此數值大於0.5,亦與從圖形上觀察具有相同的結論。
2. 顯著變數
由於利用上述方法,每一次建立模型會挑選到的變數略有不同,故將此十次訓練模型結果中,有曾出現過顯著的變數列出,予以討論。以下先舉其中一個例子,來觀察各個變數對風險指標帶來的影響。

上述輸出為十次訓練過程中的其中一次,在此訓練和測試樣本下,最後模型所挑出的變數為身心障礙-嚴重程度-中度、房屋資訊-大樓住戶數及房屋資訊-營業用面積平均,其中在這三個變數的最後一行,可以看到有*的符號,在設定顯著水準為0.5下,只要至少有一顆*,便可視為此變數為顯著,因此可看出身心障礙-嚴重程度-中度和房屋資訊-營業用面積平均為顯著的變數。
並且從Estimate欄位,可以看到這些變數的係數都大於0,代表這三個變數的數值越大,則風險機率越高。與常理相同。
綜觀十次訓練的結果,至少出現做一次*的變數如下:身心障礙-嚴重程度-中度、身心障礙-人數、房屋資訊-營業用面積平均、房屋資訊-透天住戶數及房屋資訊-大樓住戶數。
結果討論
從顯著的變數可以看出,影響一個地區(區里)火災機率的高低,取決於身心障礙的人數以及房屋資訊。獨居長者相關的資料,在此樣本中模型中,無顯著效果。
指標介紹
嚴重指標
指標定義
嚴重指標代表,發生一次火災火警的嚴重性,當指標數值越大,代表該里單次火災火警的嚴重性越高。
建模概念
每次火警或是火災都會出動車子,而每一次火災火警出動的車次數量不定,當出動車次數目越多時,亦代表該火災火警越嚴重,需要越多的人力支援。故我們利用此一特性,將我們的反應變數y定為「火災火警-總出動車次數」。
並利用「火災火警-總出動車次數」除以「火災火警-總案件數」,得到平均出動車次,即代表每個里發生一次火災平均所需出動車次。
最後將模型中的配適值 (Fitted Value) 取自然對數後依比例將所有值縮放到0%~100%,並將此值當成每一區里的嚴重指標。
建模過程
在建模過程中,我們嘗試過許多種不同的方法及模型,最後選用Generalized Linear Models,即一般線性模型來建模。
而在變數選取方面,由於現在消防局發放住警器時的順序是以弱勢族群為優先發放對象,然而這個發放的條件沒有經過實際的數據證實,只是一般性地認為這是社會上相對比較需要被關懷的對象,因此在選取變數上,挑選與弱勢族群相關的變數,以驗證此發放順序是否符合實際需要。
最後選取的變數有:身心障礙-嚴重程度-中度、身心障礙-嚴重程度-重度、身心障礙-嚴重程度-極重度、身心障礙-嚴重程度-輕度、身心障礙-人數、獨居長者-平均年齡、獨居長者-人數、房屋資訊-透天住戶數、房屋資訊-大樓住戶數、房屋資訊-工廠個數、房屋資訊-平均屋齡、房屋資訊-住家用面積平均、房屋資訊-營業用面積平均。
模型成效
利用Morisita-Horn Similarity index(衡量兩組資料是否相似的指標)去評估模型成效,搭配交叉驗證(Cross Validation)做9:1資料拆解且重複300次,然後將Morisita-Horn Similarity index取平均得出0.66,代表此模型的預測值與真實值有接近七成的相似性,所以我們認為此模型可以有效當成嚴重性指標來應用。R-sqrared = 0.629,也就是此模型可以解釋約63%的變異。
另外從模型的建模結果來看,獨居長者-人數及房屋資訊-工廠個數對於火災火警嚴重性來說,是有顯著性地影響,其解釋意義為:
◆ 獨居長者-人數:當該里獨居長者的人數越多的情況下,其火災火警案件的嚴重性相對可能也越高,推測可能原因為獨居長者獨自一人在家,當有意外發生時,較無法即刻發現通報,可能導致災情較為嚴重。
◆ 房屋資訊-工廠個數:當該里的工廠個數越多的情況下,其火災火警案件的嚴重性相對也越高。
總救災時間指標
指標定義
定義在0% ~ 100%的數值,用來評估每一區里整體救災時間的多寡,越高分代表此區里花費在火災火警的救災時間越多,反之,越少。
建模概念
將103~104年間,各區里總救災時間當成 y (predictor),利用GLM (Generalized Linear Model) 搭配統計模型選擇方法 (stepwise),並取出最高R-square的模型。
再將模型中的配適值 (Fitted Value) 取自然對數後依比例將所有值縮放到0%~100%,並將此值當成每一區里的總救災時間指標。
模型成效
利用Morisita-Horn Similarity index(衡量兩組資料是否相似的指標)去評估模型成效,搭配交叉驗證 (Cross Validation) 做9:1資料拆解且重複300次,然後將Morisita-Horn Similarity index取平均得出0.76,代表此模型的預測值與真實值有接近八成的相似性,所以我們認為此模型可以有效當成總救災時間指標來應用。
火災機率指標
指標定義
將各區里重新分類為「曾經記錄發生過火災」與「未曾記錄過火災」。
建模概念
將各區里視為一個樣本,並將這些樣本分類為兩組,一組為有發生過火災,另一組為沒發生過火災,將題目定義為分類問題。
建模方法
利用邏輯斯回歸,並搭配逐步挑選變數的方法,將所有特徵列入模型,並利用交叉驗證的方式,去訓練模型,並同時在交叉驗證的過程,去對驗證資料去做預測,來得到該區里的風險係數。而此風險係數便可定義為發生火災的機率。
模型成效
模型選擇的過程是利用ROC曲線下的面積 (AUC) 來作為指標,此值越大,則模型越佳。並將隨機亂猜的AUC (0.5) 定義為基準。而此模型的AUC為0.6428。
▼ 消防資料英雄於高雄市消防局合影

延伸閱讀
You may also like
-
黨產會專案文本分析系統
3 10 月, 2022 -

讓社工外勤不再危險
22 7 月, 2022 -

採購稽核智慧化
6 10 月, 2021
2 Comments